Zig as the foundation for a next generation game engine
Table of contents
1. Introduction
Until recent years, before Indie dev boom, most of the engines were proprietary and were tightly coupled to games that were built on top of them. Developers wishing to create a game had to do a thorough research about a target platform and write a lot of basic functionality that is now shipped in most engines by default. Appearance of Steam and Xbox Live Arcade in mid two thousands was one of the stepping stones for indie game development and it “pulled underground indie devs up into the sun” by taking care of the game distribution.1 Naturally, this caused the rise in demand for game engines. However, most of the engines at the time were proprietary, and companies behind them weren’t keen on sharing their secrets, as the industry was still in its adolescence. As a result, they were never properly researched.2
Almost all relevant game engines are closed source which means that details of how huge game projects are managed are not available to the researchers. There are some books on this topic, but they don’t provide high level architecture overview, only low level implementation. Most of the recent academic works agree that not a lot is known about the game development process, and most of the relevant information about big and successful engines come from postmortems, blogs or other media where individual developers share their experiences. The fact that they are not thoroughly researched nor defined yet and is a source of much frustration.3
Additionally, the rebirth of handhelds with Nintendo Switch, Steam Deck and other platforms means that game developers need to take more care about game optimizations since the computing power of those devices is more limiting compared to bulky PCs and consoles. Although the semiconductor industry has been good at identifying near and long term bottlenecks of Moor’s Law4, some chip-makers claim that Moor’s Law is dead, justifying the price hike of graphics cards.5 Thus, it is important to find new ways for optimizing video games within the software, instead of relying on the hardware to handle the ever-increasing load. Popular engines like Unreal and Unity allow for a faster development cycle by limiting the access to the engine’s underlying systems.
“It is our belief that the manner in which low-level issues influence architectural design is intrinsically linked to the fact that technology changes at a very fast rate”.6 For these reasons, it is important to periodically evaluate those systems and to look for possible improvements. One of them could be switching to another language. Most of the modern games are written in C++ and C3, but both of them are quite old, and were designed during a different age and for different kind of hardware that is not common nowadays - dedicated graphic cards did not exist and 4 kilobytes of RAM was a norm.
In a present day, game development cycle is very complex, especially in triple-A studios. Generating the assets and writing the code is just a tine fraction off it. Second most common kind of problem faced in the field is related to technical issues.7 Creation of a game starts from pre-production stage, with writing a game design document and scribbling the concept art. It is during this period when a project should decide what kind of engine will be used judging from the core gameplay features. A right decision at the early stage might reduce the amount of technical problems faced later by removing the excessive functionality that is common in general purpose engines like Unity, thus simplifying its usage.
In order to find possible improvements in current game development process, the following research questions will need to be answered: What are the fundamental components of a game engine? and How does a programming language impact the game development process? To answer them the following research tasks need to be performed:
- compare the features of popular game engines;
- analyze the architecture of open-source game engines and identify common components;
- compare C, C++, Rust and Zig in several features such as semantics, package management, build system, etc.;
The paper is structured as follows:
- Section 1 is a theoretical part that exposes previous researches and explains the terminology;
- Section 2.1 compares Unity and Unreal Engine;
- Section 2.2 analyzes existing open source game engines and their trends;
- Section 2.3 analyzes C, C++, Rust and Zig programming languages;
- Section 3 discusses our results and threats to their validity;
- Section 4 concludes.
1.1. Theoretical part
As mentioned earlier, academic papers that touch the topic of game engines concur that it is severely underresearched.7,8,9,2 “This lack of literature and research regarding game engine architectures is perplexing”.6 By the time of writing of this paper, several works about game engines internal architecture have been published, however, to the best of my knowledge, none has discussed the importance of a programming language. Here are the most relevant studies for our exploration.
Anderson et al. do not perform a research, but introduce fundamental questions that need to be considered when designing the architecture of a game engine.6 Although dated, this is a great introductory resource that distills the state of research of game engines. They highlight the lack of proper terminology and game development “language”, as well as the lack of clear boundaries between a game and its engine. Authors encourage classifying common engine components, investigating the connection between low-level issues and top-level engine implementation, and identifying the best practices in a field. A paper also mentions an “Uberengine”, a theoretical engine that allows to create any kind of game regardless of genre. We will come back to this study in Section 2.2.
A comprehensive book by Gregory 10 about the engine architecture is referenced in multiple studies. He proposes a “Runtime Engine Architecture”, in which a game engine consists of 15 runtime components with a clear dependency hierarchy. We take a close look at them and debate possible modifications in Section 2.2.1. This book finds an optimal middle ground between a high-level, broad description of how those modules interact with each other, and their detailed implementations. Most of the example code is written in C++, hence object-oriented in nature.
Ullmann et al.11 used this model as a target reference when exploring the architecture of three popular open source game engines: Cocos2d-x, Godot, and Urho3D. They added a separate World Editor (EDI) subsystem “because it [World Editor] directly impacts game developers’ work.” Godot was found to have all 16 out of 16 subsystems, while Cocos2d-x and Urcho3D 13 and 12 respectively. However, the missing functionality was not absent, but rather scattered among other subsystems. They also found which subsystems are more often coupled with one another: COR, SGC and LLR. COR file are helper tools that are used throughout the system. “Video games are highly dependent on visuals, and graphics are a cross-cutting concern, therefore it is no surprise that so many subsystems depend on LLR and SGC”.11 Other commonly coupled systems were VFX, FES, RES and PLA.
In their next paper12, they sampled 10 engines and found that the top-five subsystems were: Core (COR), Low-Level Renderer (LLR), Resources (RES), World Editor (EDI) and Front End (FES) tied with Platform Independence Layer (PLA). Those subsystems “act as a foundation for game engines because most of the other subsystems depend on them to implement their functionalities”. A visualized dependency graph is shown below. There are, however, other architectures used in proprietary mainstream engines, of which very little is know, and the suggested architecture is only one of the possibilities. 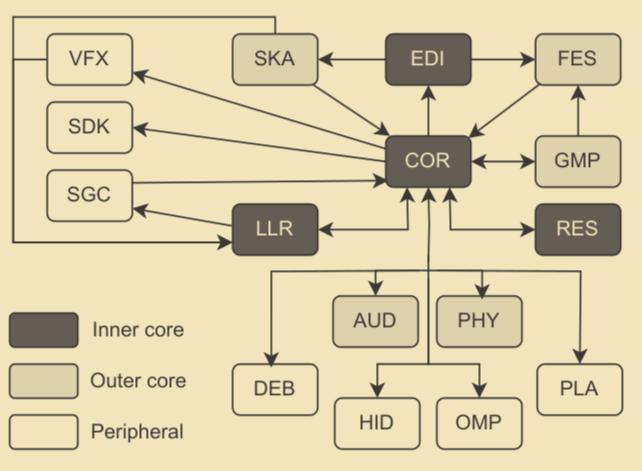
A breakdown of game development problems was performed by Politowski et al.7, where they determined that the second most common kind of problem is “technical”, sitting at 12%. First being “Design” problems - 13%, and third - “Team” with 10%. Addressing the technical issues with game engines tackles the second most common kind of problem faced in a game-development industry. This is a hint for us which parts of the next generation game engine need to be addressed.
A paper from Nederlands, written by Gunkel at al.13 describes the technical requirements of XR architecture.
(XR) Extended Reality - collective name for Virtual Reality, Augmented Reality and Mixed Reality.
One of the drawbacks of contemporary game engines is that they are designed to work with static meshes and not the environment around a user, which needs to be acquired in real-time. This problem is being solved by Spatial Computing - “widely autonomous operations to understand the environment and activities of the users and thus building the main enabler for any AR technology”. There is also a need for a metadata format that describes how and where to place an entity in a scene. The most appropriate one is glTF. “GLTF is a royalty-free format that can both describe the composition of 2D and 3D media data, as well as directly compress assets in its binary format… It is however yet to be seen if it can be established as a main entity placement descriptive format for XR”. Last point is about Remote Rendering. To render a scene with proper lighting, shadows and, perhaps, ray-tracing, a substantial processing power is needed. They conclude that game engines and multimedia orchestration “require a closer synergy, optimizing processes at various levels”.
Mark O. Riedl14 describes some of the common problems with AI in game engines. He breaks down AI problems into 2 categories: pathfinding and decision-making; and introduces 2 strategies for decision-making: finite-state machines and behavior trees. AI module takes the responsibility of datamining - analyzing how players interact with a game. This data can be used to guide the development of patches, new content, or make business decisions.
Two papers explore game-development process as a whole. Aleem et al.2 describe in thorough details common problems faced in pre-production, production and post-production phases. Hussain et al.8 define common problems during a project life-cycle, and, similarly to Politowski et al., find that the biggest contributor to the problems is management: “…scope problems, for instance, feature creep - initial scope of the project is inadequately defined, and consequent development entails addition of new functionalities which becomes an issue for requirements management”. An important practice that helps aleviating this problem is using a Game Design Document. Additionally, teams that tried incorporating Model-Based development report some success:
model-driven development here is to abstract away the finer details of the game. This is done with high-level models such as structure and behavior diagrams as well as control diagrams. … it allows management to gain at least a rudimentary understanding of the game design and help alleviate the communication problems encountered in previous development methodologies.8
Toftedahl and Engström15 in their work discovered that as of 2018 “Unity is the engine used in approximately 47 % of the games published on Itch.io”. While on Steam it comes as second (13.2%) after Unreal Engine (25.6%). They categorize game engines into 4 types:
- Core Game Engine: collection of product facing tools used to compile games to be executed on target platforms. e.g. id Tech 3, Unity core;
- Game Engine: a piece of software that contains a core engine and an arbitrary number of user facing tools e.g Raylib, Bevy;
- General Purpose Game Engine: a game engine targeted at a broad range of game genres e.g. Unity, Unreal, Godot;
- Special Purpose Game Engine: a game engine designed to create games of a specific genre e.g. GameMaker, Twine.
Because they did not quantify the exact amount of user facing tools required for a Game Engine, this research can be hardly called satisfactory and only causes ambiguity. In theory, any single utility added to a Core Game Engine makes it a Game Engine. Additionally, their definition of Core Game Engine is in contradiction with Gregory’s “Runtime Engine Architecture” where Core files are “useful software utilities” (chpt. 1.6.6)10. Unity core contains several packages including a renderer and UI16, meanwhile Gregory has a “Low-level Renderer” and “Front End” separate from “Core”. As for the Special Purpose Game Engine, it can be considered as an engine that compiles only one kind of game but with different configurations. In which case, a mod for Minecraft can be considered a game that was produced using Minecraft engine.
1.2. Game vs Non-game software
In their work “Are Game Engines Software Frameworks? A Three-perspective Study”3, Politowski et al. have explored whether game engines share similar characteristics with software frameworks by comparing 282 most popular open source engines and 282 most popular frameworks on GitHub.
Game engines are slightly larger in terms of size and complexity and less popular and engaging than traditional frameworks. The programming languages of game engines differ greatly from that of traditional frameworks. Game engine projects have shorter histories with less releases. Developers perceive game engines as different from traditional frameworks and claim that engines need special treatments. 3
Game developers often add scripting capabilities to their engines to ease the design and testing workflow, meanwhile frameworks products are often written in the same programming languages.
A similar comparison between game and non-game software has been performed by Paul Pedriana from Electronic Arts17. Most notable differences are that game source and binaries tend to be rather large, they operate on much larger application data and do not tolerate any execution pauses. Moreover, by targeting non-desktop platforms such as consoles and handhelds, which often do not have paged memory and incorporate special kinds such as physical, non-local, non-cacheable and other memories, developers must practice great care when dealing with memory management As a result, game development requires a lot more effort put into the optimization of memory usage - every byte of allocated memory must be accounted for.
Other notable difference is almost complete lack of automated testing in game development.18 Correctness of the gameplay code is not particularly important, as usually there are no concrete definitions other than “it should feel right”. Unlike in other domains, user’s safety or savings are not at stake if a program contains a bug. It is very often vice versa - a peculiar bug might lead to discovering a new and compelling game feature that will pivot a game’s further development. Parts that might adopt partial test coverage will be restricted to low-level game engine code like physics routines, network matchmaking, algorithm correctness and similar.
Nonetheless, despite the differences in those two fields, Pesce points out that game developers should not shy away to learn from other fields, even from “wasteful” Python. In particular, web services tackle modularity and hot-reloading much more efficiently, while very few engines are designed to have well-separated concerns. Theory of API development, debating them and sketching the connections of subsystems on a whiteboard are common and useful practices that game developers tend to neglect.19
1.3. Terminology
So what is a game engine?
John Carmack, and to a less degree John Romero, are credited for the creation and adoption of the term game engine. In the early 90s, they created the first game engine to separate the concerns between the game code and its assets and to work collaboratively on the game as a team.3
A game became known as Doom, and it gave birth to the first-ever “modding” community (chpt 1.3)10. Thus, a new game could be made by simply changing game files and adding new art, environment, characters etc. inside a Doom’s engine. It is hard to draw a line and try to fit this engine into a taxonomy proposed by Toftedahl and Engström as it is both a Special Purpose engine, that creates a game in a specific genre; and a Core engine, that provides useful software utilities.
Another definition for a game engine that popular engines’ websites give is as follows: “A framework for game development where a plethora of functions to support game development is gathered”.15 Jason Schreier claims that a word “engine” is a misnomer:
An engine isn’t a single program or piece of technology — it’s a collection of software and tools that are changing constantly. To say that Starfield and Fallout 76 are using the “same engine” because they might share an editor and other common traits is like saying Indian and Chinese meals are identical because they both feature chicken and rice.20
Lastly, Politowski et al. gathered multiple definitions of “game engine”:
- collection of modules of simulation code that do not directly specify the game’s behavior (game logic) or game’s environment (level data);
- “different tools, utilities, and interfaces that hide the low-level details of the implementations of games. Engines are extensible software that can be used as the foundations for many different games without major changes… They relieve developers so that they can focus on other aspects of game development”.3
In brief, all those definitions imply that an engine is foremost a collection of software tools. Applications and a code that can be reused, and allows game developers to start working on game-related problem instead of writing general utilities from scratch. It is my belief that a “game engine” is an imaginary concept that is used as an umbrella term for software tools that help with creating video games, similarly as a word “dinner” is an umbrella term for a collection of meals. Therefore, for the purpose of this paper, “game engine” will imply an ecosystem around software development, which helps with producing video games in one way or another. Development environment potentially has a significant influence on the quality of a final product, and so cannot be ignored when designing a modern engine.
Video game modding (short for “modification”) is the process of alteration by players or fans of one or more aspects of a video game, such as how it looks or behaves.21 Mods may range from small changes and tweaks to complete overhauls, and can extend the replay value and interest of the game. We cover this topic in more details in Section 2.2.7.
During the analysis of programming languages, terms “low-level” and “high-level” will be used frequently. There is no clear answer what makes a particular language high- or low-level, but it is good comparison tool. A language like C can be perceived as low-level compared to Python, because a developer is responsible for memory management; but on the other hand C might be treated as high-level compared to x86 assembly, because a developer does not work with registers directly. Again, for the purpose of this paper, lower level will suggest that a language gives software engineers more control over the hardware. In cases where those terms do not refer to the code but rather to the architecture, “high-level” means “less nitty-gritty details”.
Cargo cult programming is the practice of applying a design pattern or coding style blindly without understanding the reasons behind that design principle.
GPU is a Graphics Processing Unit. Unlike CPU, GPU can have some thousands of cores, but they are specialized to do floating point operations and do calculations in bulk. Usually, to talk to a GPU, one needs to call graphics API like OpenGL, DirectX, Vulkan etc. A renderer (or rendering engine) is a part of a game engine that is responsible for drawing pixels onto the screen. A shader is a program that is sent to the GPU to be executed, and it “runs on each vertex or pixel in isolation”.22
An important distinction we must establish is the language of engine vs language of scripting. An engine needs to run a game fast. But game development cycle also needs to be fast. For this and other purposes, an engine can integrate a scripting language. Such language is more limiting than the language an engine is written in, but it allows skipping a compilation step every time there is a new change to the game. Scripting language provides only a subset of features provided by an engine. A scripting language can be virtually anything, from a simple custom parser to full-fledged languages like C#, Lua or Python.
Now with the theory covered, we take a look at some of the popular game engines, and gather more data from concurrent blog posts and articles.
2. Research
As we have seen, Unreal and Unity are currently the most widely used game engines. The worldwide demand for Unreal Engine skills is expected to grow 138% over 10 years.23 Therefore, it is, crucial to understand what makes both of those engines appealing towards game developers.
We begin this research by answering what set of features provided by Unity and Unreal appeals to game developers and make those features our guidelines. After finding the most important ones, we take a look at open source game frameworks and analyze them based on those guidelines. The difference in analysis between Unity and Unreal and their open source counterparts will be in our point of view. First ones will be viewed from the point of view of a regular game developer, while the rest from both the game and the engine developer perspective. Then we compare languages used in all of those engines and attempt to determine whether any of the language peculiarities have had a direct impact on engine’s architecture.
Although this research is purely theoretical, we encourage readers to try to apply the findings to their own projects, because creating a practical product is an integral part of a learning process: “The only way for a developer to understand the way certain components work and communicate is to create his/her own computer game engine”.11 The second-biggest reason why new engines are being developed is because of the learning purposes, with first reason needing more control over the environment. The actual need to create a game is only on a third place.3 Although this trivial reason only comes at a third place, as game developers, we must battle test our engines by making games with them, with boring fundamental gameplay systems. Not ignoring artistic aspects of game development can help us while writing a game engine. If we get too far into development without ever making games with it, we might discover that our engine cannot make games. Many engines are supposed to be used by users, not to be a tech demo.24 There is a difference between testing new features in an empty scene and implementing them into something with actual gameplay.25
It’s easy to get so wrapped up in the code itself that you lose sight of the fact that you’re trying to ship a game. The siren song of extensibility sucks in countless developers who spend years working on an “engine” without ever figuring out what it’s an engine for.26
2.1. Unity and Unreal
There are many reasons why a certain product can gain popularity. For starters, both Unity and Unreal have entered the market quite early. Unity’s first release was in 2005, and it received a lot of attention by being completely free to use, while first version of Unreal was announced back in 1998. [31] 20 years is ample time for a product to attract users and determine the hierarchy of consumer needs. Nowadays, both engines are used for more than mere video game creation. Unreal is often being hailed as the future of filmmaking. Movie industry benefits from using it because working in real time makes things more dynamic. One can quickly visualize scenes, frame shots and experiment with the film’s “world” before committing to filming. “Unreal Engine is an incredible catalyst for world building”.27 Pre-visualisation is an area where efficiency is of utmost importance. Results need to be handled quickly and artists must respond instantly to last-minute changes. To achieve success in such environment, artists need tools that will deliver instant feedback. Unity assists artists with their dedicated AR tools, which come pre-configured with good default options and can be used straight out of the box - “This includes a purpose-built framework, Mars tools, and an XR Interaction Toolkit”.23
Both products have helped with lowering the skill floor for beginner game developers, and this technical barrier only continues getting lower. Not only new games are more graphically superior but also are much easier to make for less-technical artists. “The trend is moving towards more and more automation of the process, and towards improving the quality of the product at the final stage.”28 If this pattern proves to hold, it will mean that fewer games will be made from scratch, and more reusable assets will be recycled to make new games. For a smooth experience of asset reuse, a solid marketplace will be needed: “One of the biggest opportunities is how real-time engines facilitate exchanges via the marketplace”.28 Indeed, one prominent advantage that both engines seem to possess is an online marketplace. An artist can scroll a catalog of assets and make a game prototype in a short time span.
Despite the abundance of both free and paid 3D models available on the market, the world still needs more 3D designers. “In the world of 3D design, demand is so high that there is more work to do than there are designers to do it”.29 Perfect photorealism is becoming both more accessible and more common in design. In the future, whether filmmakers will go for a traditional camera shoot or CGI implementation will be a question of budget.29 Consequentially, with the rise in demand for 3D art there also rises a demand for a software which allows working with it.
2.1.1. Unity
In his overview of Unity, Gregory writes that the ease of development and cross-platform capabilities are its major strengths (chpt 1.5.9)10. Upon further investigation of the features of this engine, all the pros can be broken down into 3 rough categories: portability, versatility and community.
2.1.1.1. Pros
Most of the sources that construe Unity’s popularity highlight how cross-platform support greatly assists during both production and post-production phases.
…it stands out due to its efficiency as well as its multitude of settings for publishing digital games across multiple platforms… developers select and focus their efforts on developing code on a specific platform without spending hours configuring implementations to make the application run on other platforms.30
Unity game can be run on more than 20 different platforms, including all major desktops, Android, iOS, consoles like PlayStation 4 (including PS VR), PlayStation 5 (including PS VR2), Xbox One, Xbox Series S|X, Nintendo Switch and web browsers.31 Apart from being able to cross-compile a game, developers are also given a powerful suite of tools for analyzing and optimizing a game for each target platform (chpt 1.5.9)10.
This might be the paramount reason why Unity has withstood the test of time and managed to retain their user base. According to the data published by Unity Technologies, 71% of the mobile games are Unity-based.32 The ability to run a game on whichever device a player might possess significantly increases the chances of your game being picked up and played. Especially as cross-platform games gain more and more popularity with each year.33 “The possibility of fully integrating games into web browsers, at a time when mobile devices have dominated the market, is probably the future of many digital games”.30
Unity’s versatility has extended its reach beyond regular game development, finding application in the fields that require real-time simulation such as the automotive industry, architecture, healthcare, military and film production.34 A good example of a “do it all” software - a seemingly bottomless toolbox that contains the instruments useful for any professional in any industry. There is no kind of game you cannot create with it, be it 2D, 2.5D, 3D, XR etc.30 Pixel art or photorealism, card game or platformer, fps or RPG. It does not matter. Its user interface is simple enough to start prototyping without coding. Coding part can be omitted entirely with visual scripting provided by Bolt.32 “All you should know is just how to make game art. Everything else can easily be done with Unity’s tools”.33
Those tools include XR instruments (60% of AR and VR content is made with Unity34), Built-in Analytics (Real-time data and prebuilt dashboards). Game Server Hosting, Matchmaker and Cloud Content Delivery allow developer to create multiplayer games and host them on a web server. Unity Build Automation and Unity Version Control can take care of DevOps aspects of game development (47% of indies and 59% of midsize studios started to use DevOps to release quickly) Asset Manager (in beta as of writing this paper) helps with managing a project’s 3D assets and visualizing them in a web viewer.33 This is only a tip of an iceberg, and for a full list of available features you can always refer to the official documentation. Not only those features are there, Unity also releases frequent updates accompanied by major fixes to software security vulnerabilities. To top it all off, a scripting language C# provides even more versatility with the ability to support both the back-end (Azure SQL Server with .NET) and the front-end (Asp.Net) of the application.30 Unity’s adaptability to modern trends is simply fascinating and is overall a good textbook example on how to keep a game engine up to date.
Lastly, a reason that is not exclusive to the game development and can also be equally perceived as the consequence of the two previous factors is the community. More specifically marketplace and learning materials. Unity Asset Store offers a vast collection of assets, plugins, and tools that can be easily integrated into projects, saving time and enhancing development efficiency. If there is some kind of tool one might need, there is a good chance that somebody has already made it and now sells it for a cheap price on the asset store. Thus, when starting a new project, teams don’t need to start from scratch because many of the prerequisites can be simply acquired from there and be imported into a project in a matter of few clicks. “It’s better to spend a hundred dollars on the Unity Asset Store instead of doing something that would cost twenty or thirty thousand dollars and two to three months to develop”.33 By staying on the market for so long and being used in various projects of a varying caliber, it is no surprise that abundance of tutorials and code snippets can be found online. The amount of learning materials for Unity exceeds those of any other engines out there, even Unreal.35
2.1.1.2. Cons
Now let’s discuss Unity’s shortcomings. Biggest one stems from its desire to be versatile. A freshly created, empty 2D project can weight up to 1.25 GB, and PackageCache folder up to 1 GB. Although certain dependencies can be manually removed from “Packages/manifest.json”, most of the modules are deeply intertwined with Unity’s core, and removing them would be shortsighted and could lead to bugs. This bulkiness is fine for the modern hardware, but a resource-hungry behemoth is not ideal when a game needs to be run on an older hardware or power-efficient devices. Unity was found to have issues with CPU and GPU consumption and modules related to rendering.30 Not everyone who wants to play video games can afford a modern computer or a phone. Unity also doesn’t support linking external libraries.32 This factor cripples its possibility to be modular. Additionally, with constant technological innovations, computing power can be placed inside many unconventional targets like smart fridges, digital watches, thermostats etc. But “while Unity’s cross-platform support is a significant advantage, it can also lead to suboptimal performance on certain platforms. Games developed in Unity may not perform as well as those developed using native game engines specifically designed for a particular platform”.35 Being able to play a Snake game on a smart oven would be a neat little feature worthy of buying it.
Moreover, despite showing a great adaptability, Unity Technologies’s leadership sometimes make for-profit business decisions that are often not perceived well by the community, such as one of their latest announcements about a “Runtime Fee”, which charges developers each time a game using the engine is downloaded.36 This decision was harshly rebuked by community and was eventually changed to apply only to games created with Unity Pro and Unity Enterprise. Nonetheless, this company has shown themselves capable of trying to pull the rug out from under developers and not hesitating to squeeze them into debt with per/install (released game) royalties and other loathsome shenanigans. Problems like this are absent, as a rule, in open source game engines, some of which we discuss later.
Lastly, Unity might suffer from an identity crisis. It is supposed to be a “build anything” engine used by both indie and triple-A studios alike, however many indie studios do not need “anything”, they simply need the tools to make a game of a particular genre. Trying to branch out into too many spaces at once instead of focusing on what they are good at is a sign of a capitalistic greed, and it might bite them in the future. When the abundance of specialized software exists - software that is designed to excel at a small subset of features, why would a company that needs those specific features pick Unity?
2.1.2. Unreal Engine 5
Similar to Unity, Unreal Engine can be used for much broader purposes than to just create video games. It is more fitting to think about it as a real-time digital creation platform used for creating games, visualizations, generating VFX and more.37 In particular, filming industry has been eagerly adopting it in recent years, being successfully used in numerous popular movies and TV series like “Fallout”, “Love, Death + Robots”, “Mandalorian”, “House of the Dragon” and many more.38,27 Virtual Camera system allows controlling cameras inside the engine using an iPad Pro.37 Gregory claims that this engine has the best tools and richest engine feature sets in the industry, and that it can create virtually any kind of 3D game with stunning visuals (chpt 1.5.2)10.
Unlike Unity, however, its huge arsenal of tools does not seem to be forcing a company to grow in every direction all at once. Unreal’s identity is strikingly clear - its job is to produce the best-looking graphics possible. It is also mindful that plenty of AAA studio with large teams are using this engine and that team roles there are more diverse than in smaller studios, so the tools that are given to the artists vary in degree of complexity but are rather artist-friendly, and the workflow for meshes and materials is similar to that of native 3D software like Blender or Maya. Visual scripting in a form of Blueprints is an integral part of an engine’s world editor (unlike visual scripting solutions in Unity that exist only as external plugins). Built-in version control system allows including a new team member into a project and easily merge new changes into a scene that a team is currently working on. Arguably Epic Games’ most famous project Fortnite not only showcases some of the extents of its engine, but also serves as a platform for game development with Unreal Editor for Fortnite (UEFN). Games created with UEFN can be directly published to the Fortnite platform, reaching a built-in audience of millions.39
2.1.2.1. Graphics
Undoubtedly, the primary driver behind Unreal Engine’s widespread adoption is its ability to produce stunning visuals. Let’s delve deeper into these graphics-centric advancements. Three of the most talked about technologies are Lumen, Nanite and Virtual Shadow Maps. 
Lumen is a global illumination and reflections system. It is fully dynamic which means there is no need for light baking. Its “primary shipping target is to support large, open worlds running at 60 frames per second (FPS) on next-generation consoles”.40 It does not work on PlayStation 4 and Xbox One. Lumen provides 2 methods for ray tracing: software ray tracing and hardware ray tracing. Software ray tracing is more limiting as there are restrictions on what kind of geometry and materials can be used e.g. no skinned meshes. Lumen Scene operates on the world around the camera, hence fast camera movement will cause Lumen Scene updating to fall behind where the camera is looking, causing indirect lighting to pop in as it catches up. This system works by parameterizing surfaces in a scene into Surface Cache which will be used to quickly look up lighting at ray hit points. Material properties for each mesh in a scene are captured from multiple angles and populate Surface Cache. Lumen calculates direct and indirect lighting for these surface positions, including sky lighting. For example, light bouncing diffusely off a surface picks up the color of that surface and reflects the colored light onto other nearby surfaces, also known as color bleed. Diffuse bounces are infinite, but Lumen Scene only covers 200 meters (m) from the camera position (when using software ray tracing). For the fullest potential of Lumen, it is recommended to use hardware-accelerated ray tracing, which raises a question how much of a Lumen’s success lies with its software innovation as opposed to just the utilization of new features provided by the latest hardware of graphics cards.
Nanite is a Level Of Detail (LOD) system. “A Nanite mesh is still essentially a triangle mesh at its core with a lot of level of detail and compression applied to its data”.41 Nanite can handle orders of magnitude more triangles and instances than is possible for traditionally rendered geometry. When mesh is first imported into a scene, it is analyzed and broken down into hierarchical clusters of triangle groups. This technique that might be similar to Binary Space Partitioning. “During rendering - clusters are swapped on the fly at varying levels of detail based on the camera view and connect perfectly without cracks to neighboring clusters within the same object”.41 Data is streamed in on demand so that only visible detail needs to reside in memory. Nanite runs in its own rendering pass that completely bypasses traditional draw calls. Overall, this addition to an engine allows building extremely complex open worlds with astonishing amount of details. Filming industry can abuse Nanite by importing high fidelity art sources like ZBrush sculpts and photogrammetry scans. Although it is good for complex meshes when doing cinematography, there are struggles with rendering a game at 60 FPS, in which case a manual optimization of LODs is preferred over relying on automatic LODs from Nanite.42
Virtual Shadow Maps (VSM) is a shadow mapping method used to deliver consistent, high-resolution shadowing. They need to exist in order to match highly detailed Nanite geometry. Their goal is to replace many stationary lights with a single, unified path. At the core they are regular shadow maps but with high resolution (16k x 16k pixels). However, in order to keep performance high at reasonable memory cost, VSMs are split into Pages (small tiles) that are 128x128 each. Pages are allocated and rendered only as needed to shade on-screen pixels based on an analysis of the depth buffer. The pages are cached between frames unless they are invalidated by moving objects or light, which further improves performance.43 Since VSMs rely on Nanite, they might suffer from similar performance issues.
There are many more fascinating tools and features in this engine like Datasmith (import entire pre-constructed scenes), Niagara (VFX system), Control Rig (character animations), Unreal Insights (profiling) and an elaborate online subsystem which aids with handling asynchronous communication with a variety of online services. Unfortunately, the review of those modules as well as popular plugins is a topic on its own and deserves a separate paper. We do take a brief, high level look at the architecture of its codebase, however, before exploring what drawbacks are present in this engine have.
2.1.2.2. Architecture
Unreal’s build system is called UnrealBuildTool. A game is a target built with it, and it comprises from C++ modules, that implement a certain area of functionality. Code in each module can use other modules by referencing them in their build rules, which are C# scripts. This system is not much different from CMake, autotools, meson etc. Modules are divided into 3 categories: Runtime, Editor functionality, and Developer tools. Gameplay related functionality is spread throughout Runtime modules, some of the most commonly used are:
- Core: “a common framework for Unreal modules to communicate; a standard set of types, a math library, a container library, and a lot of the hardware abstraction”.44
- CoreUObject: a base class for all managed objects that can be integrated with the editor. It’s the central object in the whole object-oriented model of an engine.
- Engine: functionality associated with a game (game world, actors, characters, physics, special effects, meshes etc.).
Modules enforce good code separation, and although it does not necessarily make Unreal modular in a traditional sense, developers are able to specify when specific modules need to be loaded and unloaded at runtime based on certain conditions. Include What You Use (IWYU) option further helps with compilation speeds - every file includes only what it needs, instead of including monolithic header files, such as Engine.h or UnrealEd.h and their corresponding source files. As for the gameplay programming, scripts are written in C++ like an engine itself, and they use inheritance to expand the functionality of new objects (Actors). There is a visual scripting language called Blueprints that allows to create classes, functions, and variables in the Unreal Editor. Another option for scripting is Python, however it is still in experimental stage. It is a good option when one needs to automate his workflows within the Unreal Editor.
2.1.2.3. Cons
As for the drawbacks of this engine, perhaps the biggest one would be the consequence of trying to optimize toward the next generation graphics targets. All those innovative systems listed earlier cannot be fully taken advantage of if a game is being run on moderately powerful graphics cards prior to 20 series.45 Out of all game engines we discuss in this paper, Unreal editor is the most resource hungry and causes frequent stuttering. These performance issues make it hard to recommend this engine for developers with a limited budget and who want to target a variety of dated platforms.
Another noticeable issue arises when working with C++. Oftentimes writing scripts feels like writing a new dialect of C++ where one needs to learn specific macros and naming conventions. A lot of Unreal’s code has poor encapsulation. Many member variables are public in order to, presumable, support the editor and blueprint functionality. Some public member functions should never be called by users, like the ones that manage the “lifetimes” of objects, but they are called by other modules of an engine. This clutters the interface of many objects, making it difficult to figure out what are the important interface features of unfamiliar classes. It is also difficult to make use of RAII due to how Unreal Engine handles the creation of UObject-derived objects. Managing the state of the objects via initialization/uninitialization functions requires more caution compared to traditional C++, and it is not uncommon for complex objects to have certain parts with a valid state while the rest is not.
Other cons are less problematic and are rather subjective. For example people on forums claim that the documentation is lacking. What they actually imply is that either API reference is outdated (which is often the case for massive projects with frequent release cycles), or that a manual does not explain certain game development concepts in enough details, which is hardly an engine’s fault. A steep learning curve is not a problem but a price that game developers need to pay to work on next generation games. Tim Sweeney, a founder of Unreal Engine says
You can’t treat ease-of-use as a stand-alone concept. It’s no good if the tools are super easy to get started with, so you can start building a game, but they’re super hard to finish the game with, because they impose workflow burdens or limited functionality.46
Workflow for 2D games is not great, but from the very start of this engine, it was focused on developing shooters or first-person games.30 2D is simply not its specialization to begin with. A need to use C# for build scripts is a peculiar decision, but there is no universal way to build C++ applications and probably never will be, this is a problem of the infrastructure around the language of choice and not of the engine. Lastly a marketplace is big, and it is integrated very well into the engine and Epic store, but it certainly could be improved. There are not enough filters to search for assets, and many of them are either unfinished, broken or have licensing issues which makes them impossible to use in commercial products.
2.1.3. Takeaways
Unity and Unreal stand as titans in the game development landscape. Their long histories as free game engines make it a challenge for newcomers to dethrone them from the top. Both implement a royalty system for commercially successful games (Unreal at 5% above $1 million USD in sales, and Unity with variable plans). Source code of both engines is proprietary, but can be accessed nonetheless: Unreal on GitHub and Unity by paying for Enterprise or Industry editions. Games made with Unreal seem to scale up better than Unity, as Epic appears to have built a more robust infrastructure around the whole process of game development instead of simply giving developers the tools to make vide games. Meanwhile, Unity struggles with handling AAA games with large landscapes and heavy on-screen elements.33 Yet it appears to be a better choice for newcomers, as the skill floor is lower and the amount of learning materials (mostly community generated) is higher. It is also an engine of choice for serious games, as a final game can be easily exported to more platforms (including web browsers) with a price of using more computational resources, and the diversity of possible game genres and themes is superior to that of Unreal.
Neither engine, however, provides any meaningful tools to solve the problems of the pre-production phase of game development that were described in 2. Requirements specifications for emotions, gameplay, aesthetics and immersion exist outside the engine, which makes developers not responsible for adhering to those requirements. This opens an opportunity for incorporating high level game system description languages (external schema) into the engine, which in its turn requires Game Design Documents to be an integral part of an engine.
Importantly to the objective of this paper, we distinguished 4 key elements responsible for the popularity of a game engine:
- Portability. Developers want to work on games instead of figuring out how to port them to certain platforms. The more target platforms a game engine supports - the more likely it is to be used. NOTE
To develop for consoles, one must be licensed as a company. Console SDKs are secret and covered by non-disclosure agreements. Therefore, no game engine under an open source license is allowed to legally distribute console export templates.
- Versatility. Nobody knows how a final game will look like from the start and what systems will it need. Having every possible tool available is a safety precaution that permits to do drastic changes that can impact a game’s future vector of development
- Graphics. Even when visual fidelity is not the primary goal, everybody wants their games to look beautiful.
- Community. Games are not created in isolation from scratch. A good engine needs to have a straightforward way of integrating community generated content, be it code snippets or assets. For these purposes, it is crucial to have a first-class support for developing external plugins and assets via a marketplace. Knowledge needs to be passed and re-applied, and a game engine can serve as a playground to apply this knowledge and to battle test new ideas and techniques.
Now with those four criteria in mind, we compare some of the popular open source engines as well as try to find what other points need to be considered when designing a game engine.
2.2. Engine Analysis
This section begins by examining the research questions posed by Anderson and friends6 which will serve as a starting point for formulating the requirements of a next generation game engine. We then analyze the Runtime Engine Architecture (RTEA) introduced by Gregory and define the responsibilities of each module. Then we take a look at common game world models that describe how game objects are to be managed inside the engine. This is followed by a comparative analysis of several open source engines and frameworks: Raylib, SDL2, Bevy and Godot; contrasting their architecture with the RTEA model. Finally, we expand on the potential responsibilities of a general purpose engine and whether game modding should be treated as the extent of game development.
Questions, or rather topics of concern, raised by Anderson et al. are as follows:
- The lack of standardized “game development” terminology. How to properly define any given engine and each of its components as well as other aspects relating to game development?
- What is a Game Engine? Where’s a line between a complete game and an engine that was used building it?
- How do different genres affect the design of a game engine? Is it possible to define a game engine independently of genre?
- How do low-level issues affect top-level design? Are there any engine design methods that could be employed to minimize the impact of the future introduction of new advancements in computer game technology?
- Best Practices: Are there specific design methods or architectural models that are used, or should be used, for the creation of a game engine?
Since we will be revisiting those questions frequently throughout the entire paper, and we do not want to confuse them with the research questions of this paper, we need to come up with a convenient acronym for them. To do the justice to all authors, we will combine 2 letters of their family names into one word: AN-EN-LO-CO; consequently the questions will be ANENLOCO-[1-5]. ANENLOCO-5 requires a separate quantitative research and is outside the scope of this paper. ANENLOCO-2 was partly answered in Section 1.2 - game engine refers to the whole software development ecosystem which helps with producing video games. Whether such treatment is optimal or not is certainly up to debate, but in order to make the most diligent research, we need to take into account not only the runtime components of the engine, but also third-party tools used for creating game assets. By taking them into account, we gain a better ability to trace the roots of any particular problem - whether a tool creates it and leaves it to the engine to solve, or merely adapts to the need of an engine which created a problem in the first place. To answer ANENLOCO-4 and not viewing the whole picture of the entire game’s development stack is, at the very least, nearsighted.
2.2.1. Runtime Engine Architecture

First distinction Gregory makes is separating a tool suite from runtime components (chpt 1.6)10. Tools include the software used for asset creation like Blender and Maya for 3D meshes and animations, Krita and Photoshop for textures, Ardour and Reaper for audio clips, etc. Those digital content creation (DCC) tools are separated from the engine and do not need to know anything about each other. Tool suite also includes a version control system and instruments around a programming language (compiler, linker, IDE). With other elements this distinction becomes less apparent - what should be a part of the RTEA, and what should belong to a tool suite?
For example, performance analysis tools (profilers) vary in degree of complexity: some of them are standalone programs that only require a compiled executable, such as Valgrind, while others are designed to be injected into code to profile certain parts of a program, like Tracy. Similarly, debugging can be done either with an executable using GDB, or a primitive manual console-logging/line-drawing for a quick and dirty visual feedback. Even operating system submodule is ambiguous and cannot be easily classified into neither a tool suite nor RTEA, as it provides a slew of drivers, system packages and a libc, while simultaneously being the foremost important tool for any artist or developer and the core dependency of every DCC.
Another element of a tool suite is the asset conditioning pipeline. It is the collection of operations performed on asset files to make them suitable for use in the engine by either converting them into a standardized format, a custom format supported by the engine or a binary. To put it simply, it is a file compression/decompression system. The issue with this module is that a lot of DCC software allows integrating custom plugins that will take care of exporting an appropriate format from them, eliminating the asset conditioning pipeline altogether, making this module entirely arbitrary if it doesn’t describe the contract between DCC and the engine.
A similar peculiarity also strikes Resource Management (RES) module. It provides an interface for accessing different kinds of game assets, configuration files and other input data, making it a logical cog in the machinery of the engine. However, to scale a game up painlessly, an engine needs a database in order to manage all metadata attached to the assets. This database might take a shape of either an external relational database like NoSQL - thus making RES depend on the unaccounted for DCC software; or a manual management of text files, which than will be handled exclusively in the engine’s RES module.
Lastly, the icing on the cake, a cherry on top is the World Editor (EDI) - a place “where everything in a game engine comes together” (chpt 1.7.3)10. “Scene creation is a large part of game development and in many cases visual editors beat code”.47 Consequently, to have a visual world editor an engine needs to be logically assembled, which makes this submodule to reside at the top of the dependency hierarchy. It can be architected either as an independent piece of software, built on top of lower layer modules, or even be integrated right into a game. A world editor allows to visually create and manage both static and dynamic objects, navigate in a game world, display selections, layers, attributes, grids etc. Some examples of world editors integrated into games are shown bellow. Weirdly, Gregory classifies a World Editor as a part of the tool suite.

Runtime components are what makes up the rest of the typical engine, and normally they are structured in layers with a clear dependency hierarchy, where an upper layer depends on a lower layer. Similarly to a tool suite, it is not always obvious which category a certain submodule should belong to. Third-party SDKs and middleware (SDK) module lay at the lowest layer of RTEA right above an operating system (OS). SDK is the collection of external libraries or APIs that an engine depends on to implement its other modules. This might include container data structures and algorithms; abstraction over graphics APIs; collision and physics system; animation handling etc. Platform Independent Layer (PLA) acts as a shield for the rest of the engine by wrapping platform specific functions into more general, platform-agnostic ones. By doing so, the rest of the engine gets to use a consistent API across multiple targeted hardware platforms, as well as having the ability to switch certain parts of SDK with different ones. Core Systems’ (COR) exact definition is vague: “useful software utilities”, but some of its responsibilities include: assertions (error checking), memory management (malloc and free), math, common data structures and algorithms, random number generation, unit testing, document parsing, etc. Such breadth of facilities inadvertently raises a question whether a standard library provided by a language can be considered a Core engine system. We discuss this possibility in Section 3.4. These three components (SDK, PLA, COR) as well as RES and potentially OS form the base for any game engine, even in simple cases when the entire functionality can reside in a single file.
Another essential collection of modules is grouped into a rendering engine. Rendering is the most complex part of an engine and, similarly to base components, most often architected in dependency layers. Low-Level Renderer (LLR) “encompasses all of the raw rendering facilities of the engine… and draws all of the geometry submitted to it” (chpt 1.6.8.1)10. This module can be viewed as Core but for a rendering engine. Scene Graph/Culling Optimizations (SGC) is a higher-level component that “limits the number of primitives submitted for rendering, based on some form of visibility determination”. Visual Effects (VFX) includes particle systems, light mapping, dynamic shadows, post effects etc. Front End (FES) handles UI, aka displaying 2D graphics over 3D scene. This includes heads-up displays, in-game graphical user interface and other menus.
The rest of RTEA consists of smaller, more independent components: Profiling and Debugging tools (DEB), Physics and Collisions (PHY), Animation (SKA), Input handling system (HID), Audio (AUD), Online multiplayer (OMP) and Gameplay Foundation system (GMP) which provides game developers with tools (often using a scripting language) to implement player mechanics, define how game objects interact with each other, how to handle events, etc. Taking a look back at Unity, GMP’s subsystems in there are by far the most scarce out of all modules - the burden of defining and implementing them is entrusted onto game developers. Such approach allows Unity to be virtually genre-agnostic, and as such gives us a strong hint to answer ANENLOCO-3 - defining an engine independent of a game’s genre.
The last component is called Game-Specific Subsystems (GSS). Those are the concrete implementations of particular gameplay mechanics that are individual to every game, and highly genre-dependent. That’s a component the responsibility for which gradually shifts from programmers towards game designers. “If a clear line could be drawn between the engine and the game, it would lie between the game-specific subsystems and the gameplay foundations layer” (chpt 1.6.16)10. Therefore, this piece lies outside RTEA, as those subsystems are genre-dependent and closely coupled with a final game, giving it its unique characteristics. Gregory’s statement gives us a hunch to the answer for ANENLOCO-2, however he then adds that on practice this line is never perfectly distinct, which further enforces our point that an engine is just a notional term.
Regarding this, an interesting point is made by Fraser Brown, a developer of a strategy game “Hearts of Iron” by mentioning that an engine of their game is actually split into two parts. One is called Clausewitz, which is “a bunch of code that you can use to make games. You could use it to make a city-builder, a strategy game, an FPS… not that it would give you any tools for that, but you could…”48 And another is Jomini, which is “specifically for the top-down, map-based games”. Yet despite there being two of them, “the pair are two halves of the same engine”. This separation allows them to share the core technology across their other projects and make a development cycle much faster. It is safe to assume that Jomini is where a game’s genre is being determined, and it seems that it accomplishes the same tasks described in GMP and GSS modules of RTEA.
Despite the fact that Gregory lists in great details possible submodules for each runtime component, the biggest issue of his architecture arises with the inclusion of multiple SDKs which act not as independent utilities but rather as mini frameworks encompassing the functionality of multiple components. In other words, unless an engine is written entirely from scratch, the addition of external libraries risks in an engine to have multiple places where one particular logic is being implemented, which causes the ambiguity of concerns and really hurts its modularization. Thus, tight coupling between subsystems becomes inevitable as a project grows in size, but there is nothing supernatural about it, as was manifested by Ullmann and the crew.12 The problem is not with the coupling per se, but rather with the lack of a universal description of this engine subsystems coupling - an issue described by ANENLOCO-1. When a single external library implements the functionality of multiple submodules, it is up to an individual engine developer to decide how to design the architecture with multiple external libraries that require each other’s functionality. Unfortunately, “often authors present their own architecture as a de facto solution to their specific problem set”.6 This dilemma is what causes game engines to still be a gray area in academic circles, as was mentioned in the beginning.
As an example, let’s take a look at bgfx - a cross-platform rendering library written in C++. Trying to fit it inside RTEA proves to be a cognitive challenge as there are 4 potential runtime components that are mainly or partially responsible for providing the functionality supplied by bgfx. First is obviously SDK - an interface that allows an engine to talk to the hardware; 2) PLA, as it provides a unified API across different platforms; 3) LLR - draw whatever geometry is submitted to it (geometry primitives are not included); 4) SGC - occlusion and LOD for conditional rendering. Thus, if an engine is to be built on top of bgfx, its architecture would differ from RTEA because its rendering engine would be split in two: two out of four components (LLR, SGC) are provided by an external package, and other two (VFX, FES) will have to be either implemented in the engine, or be imported from another package (it is extremely unlikely that a library will provide VFX and FES functionality independently of a rendering engine). Apart from bgfx, there are countless game-related frameworks varying in caliber that are meant to be used as either a part of another engine or a self-sufficient tool to make games.
While Gregory’s RTEA is not the only framework for game engine design, as was pointed out by 12, its comprehensive delineation of components makes it an extremely valuable model for understanding the complex workings of modern game engines. An alternative to splitting game development tools into engine components (RTEA) and tool suite (DCC) is proposed by Toftedahl and Engström in their “Taxonomy of game engines”. Engine is split into 3 groups: 1) Product-facing tools which is essentially most of the engine’s functionality; 2) User-facing tools allow designers and game developers to create game content (GMP); 3) Tool-facing tools are the plugins that bridge different components of an engine with DCC.15
Having explored the basis of RTEA, we can turn our attention to the architecture of a game world - the design and communication patterns of objects within the game itself. While engine architecture focuses on the underlying systems that power the game, game world model deals with the structure of the game’s content and logic. This distinction is crucial in answering ANENLOCO-2, “Where is the line between a complete game and the engine used to build it?”.6
2.2.2. Game World Model
First, we need to understand the principles of a software architecture, and why is it important to have one in a project. Every program has some organization, even if it’s just “jam the whole thing into main() and see what happens”.26 Writing code in such way and without a second thought will get increasingly harder the further it gets. A software architecture is a set of rules and practices for the code based on the project’s goals. If there’s two equally good ways to do something, a good architecture will pick one as the recommended approach. Each feature or component should be implemented similarly to the other features and components.49 For a game development example, if a design requires a developer to spawn an enemy at a random location, a good architecture should specify which random number generation algorithm to use.
Joanna May, a Godot game developer, suggests that “a good architecture should take the guesswork out of what should be mundane procedures and turn it into something you can do in your sleep”49 and lists following points that a good architecture should describe:
- Organization: where to put code and assets;
- Development: what code to write to accomplish a certain feature;
- Testing: how to write tests;
- Structure: how to get and use dependencies;
- Consistency: how to format code;
- Flexibility: what happens when there’s a need to refactor something.
Robert Nystrom, an author of “Game programming patterns” book, additionally stresses that “Architecture is about change. The measure of a design is how easily it accommodates changes”. The more flexible a game is, the less effort and time it takes to change it, which is paramount during game development’s production phase, as good design requires iteration and experimentation. However, gaining high level of flexibility means “encoding fewer assumptions in the program… but performance is all about assumptions. The practice of optimization thrives on concrete limitations”. For example, knowing that all enemies in a level are of the same type, it becomes possible to store them in a single static array, which makes iterating on them faster, as opposed to storing pointers to different enemy classes and dereferencing them every loop iteration. This quandary is reminiscent of Heisenberg’s uncertainty principle: the more you focus on optimization, the more difficult it becomes to introduce changes into the game, while the more flexible it is, the fewer places for optimization there are. Bob brilliantly concludes that “There is no right answer, just different flavors of wrong”, yet in his opinion it is “easier to make a fun game fast than it is to make a fast game fun”.26 This is partly what Ms. May implies by a second key goal of a good architecture: what kind of code to write to hit the optimal middle ground between flexibility and performance. If we take a further look back, we see that exact same question is raised in ANENLOCO-5.
Another goal of software architecture is to minimize the amount of knowledge a developer is required to have before he can make progress.26 This is why software introduces abstraction layers - to hide the complexity of underlying lower level systems behind a couple of function calls. Abstraction also helps with removing duplication, which many software engineers are taught to avoid in pursuit of a clean code, but this is a double-edged sword. When adding an abstraction layer, you are adding extra complexity and speculating that it will be needed in the future either by yourself or other developers. When it is - congratulations, you have become the next Dennis Ritchie; but when it only covers some of the cases, and there is a need to pass extra parameters to cover edge cases - the opposite of the original goal was achieved. Now developers need to understand more code to add new changes. “When people get overzealous about this, you get a codebase whose architecture has spiraled out of control. You’ve got interfaces and abstractions everywhere. Plug-in systems, abstract base classes, virtual methods galore, and all sorts of extension points”.26 Regarding this problem, Sandi Metz remarks that “Duplication is far cheaper than the wrong abstraction”.50 Although in theory it is simple to follow, in reality there is almost never an obvious answer when the introduction of new abstraction is safe, let alone mandatory. Since one of the aims of this paper is to discover optimal organization of game engine components and how they can be reused, I believe that at the lowest level there should be as little abstraction as possible, because abstraction implies generalization of a problem which in turn prevents applying the optimal solution to niche problems at critical sections.
Having understood the purpose of a good architecture, let’s see how it works in practice. Once an aspiring game developer has planned out the entire plot and gameplay for his magnum opus game of the year, and has picked the according tools to build such a game, it is time to start populating a game world with static (meshes of buildings, vegetation, terrain, etc.) and dynamic (enemies, main character, etc.) objects. Those objects are often called by a mysterious name “game object” (GO) or in some cases “entity”. Anything that can be placed into a game world is a game object. A game world consists of one or more “game scenes” (levels), which are loaded and unloaded on demand. But how does one describe a game scene - what are the relations between GOs, how to update them and in which order, how to store them in memory, where should the logic of operating on those objects live? This is the job for Game World model - the specification of how to organize base building blocks for every gameplay-related aspect. From the information I could gather, there are 4 common models, which take roots from regular software development paradigms.
2.2.2.1. Procedural Model
The simplest way to organize GOs is to do it in good ol’ days without abstraction - break them down into small data structures and functions (procedures) that perform logic on them. Original Doom was written this way, as well as many other games in 80s and 90s when procedural way of programming was widespread. Early graphics APIs were also based on this approach. Unlike two other models that we take a look at next, both of which can be described by set of restrictions, procedural model, in essence, is the absence of restrictions - anything goes. It is the most straightforward and least interesting approach towards GOs organization, but it is considered to be efficient both in terms of performance and memory usage51 - key concerns for graphics rendering. The biggest downside of such model is how difficult it is to scale a world because every action of a GO requires a separate procedure that cannot be easily shared by other GOs. Hence, for modern game development in AAA studios this strategy is but a relic of the past, although for simpler games with small teams such strategy is perfectly viable.
2.2.2.2. Object-Component Model (OCM)
Robert Anguelov, a game engine developer, explains this model and gives it this name in his video presentation.24 This model is based on classic Object-Oriented programming in software engineering and has evolved over years and became the de facto model in modern game development, however it is not standardized and there are numerous different flavors. The basic principle is that a GO owns components. For instance, Player has Movement, Camera, Weapon and whatnot. (many engines have different names for a parent object: Actor, Pawn, Entity, etc.) GOs have their own init and update logic, while components may or may not have it (depends on an engine). GO can reference other GOs and components. Component stores data (references, settings, runtime state) and logic. It can reference other components and GOs. GOs and components can form hierarchies to avoid unnecessary duplication - derive different enemies from a base enemy pawn. Spatial hierarchies, in particular, are not only possible but are fundamental to describe the location of GOs in a scene. In Unreal Engine a Scene object (root) has a transform component and every GO’s position in a world is relative to that transform. Other engines might implement different spatial data structures such as scene graphs, spatial partitioning, and bounding volume hierarchies.13
OCM offers several significant advantages in game world architecture. Primarily, it allows for comprehensive representation of scene elements - GO can describe an element of the scene in its entirety (e.g. a character comprising a capsule, 5 skeletal meshes, 1 static mesh and all the logic). This conceptual simplicity facilitates intuitive reasoning about what exactly should belong to which object, which vastly simplifies the job for designers. OCM’s friendly scene-tree approach allows for easy visualization and navigation in complex game worlds as well as creating tooling (world editor integrations) to manage it. Such structure is modding friendly as it allows creating new objects by simply tinkering their components via scripting.52 Although not common, but OCM naturally goes well along with a feature-based file structure where any files that get shared between GOs live in the nearest shared directory instead of being split into ‘scripts’, ‘textures’, ‘scenes’ and likes. For instance, everything a “coin” needs lives in a coin directory - code, textures, audio, etc.49
Nevertheless, there are several disadvantages to be aware of, which are mostly derived from the typical problems faced in regular OOP like deep hierarchies or diamond inheritance. Firstly there are dangers of “Reference/Dependency hell” - functions like GetOwner(), GetObject(), GetComponent() can return references from anywhere which can cause cyclic dependencies and deadlocks. To solve this matter, one needs to be explicit with the order of initialization (and consequentially the update order with something like update priority) and data transfer, which is quite an undertaking when the amount of unique objects exceeds few hundreds or even thousands. Another way to solve this is demonstrated in Unreal Engine by unifying components - USkeletalMeshComponent is a combination of animation, deformation, physics, cloth and some other components. This approach of data storage is not cache friendly because data is not stored near each other in memory, however due to the power of modern CPUs, this shortcoming is not manifested in average-sized games, and only becomes apparent in large projects. Most codebases with OCM end up a web of inter-component/object/singleton dependencies, which is nearly impossible to untangle partly because there are hundreds of ways to decompose the GO system problem into classes, and partly because of the time constraints faced in game development, which often result in “prototypes” being the final solutions. This in turn limits the reusability of components, which was one of the primary goals of this approach.24
OCM fosters many design patterns applicable to regular OOP such as observer (subscribe to events of an object) and state (alter object’s behavior based on its state) patterns, as demonstrates Joanna May within Godot engine.
State machines, their big brothers state charts and behavior trees are integral part of almost any game and are not exclusive to this model.
She separates responsibilities into 3 levels: the lowest is called “Data layer” which is essentially most of the engine’s modules described by RTEA except GMP; higher in hierarchy is a “GameLogic layer” which is responsible for manipulating the game and its mechanics (GMP module of RTEA + Game-Specific subsystems (GSS)); and at the highest level is “Visual layer” - pure visual representation of GOs in a scene without its own logic, governed by a state machine. GameLogic layer is additionally split into two parts:
- Visual GameLogic - “code that drives their visual components by calling methods on them or producing outputs that the visual game component binds to”. In other words state machines that are specific to certain visual components. “An ideal visual component [from Visual layer] will just forward all inputs to its underlying state machine [Visual GameLogic layer]”.
- Pure GameLogic - “game logic that’s not specific to any single visual component. Implements the rules that compromise a game’s “domain” [genre]. A good state machine, behavior tree, or other state implementation [Visual GameLogic] should be able to subscribe to events occurring in repositories [Pure GameLogic], as well as receive events and/or query data from the visual component [Visual layer] that they belong to“.49
Suggested architecture perfectly complements Gregory’s RTEA (which is also object-oriented at the core) and in particular explains how to organize Game-Specific Subsystems which are not part of the game engine itself. It’s worth mentioning that Gregory differentiates two distinct but closely interrelated object models:
- Tool-side object model - GOs that designers see in the editor;
- Runtime object model - language constructs and software systems that actually implement tool-side object model at runtime. It might be identical to the tool-side model, or be completely different (chpt 15.2.2)10.
Somewhat similarly, Scott Bilas a developer of Dungeon Siege, distinguishes Static GO hierarchy - “templates that determine how to construct objects from components”, and Dynamic GO hierarchy - “GOs as described by a template that are created at runtime, die and go away”.53 Hierarchy of static objects, as well as their base properties can be described by external schema. The reason for this is that “designers make decisions independently of engineering type structures and will ask for things that cut across engineering concerns”.
2.2.2.3. Entity-Component-System (ECS)
This rather radical architecture gained popularity very recently treats GOs (entities) as a database and game logic is performed by querying specific components.52,53 The purpose of this model is to decouple logic from data to allow a game to be highly modular and flexible. An entity is simply an ID, meaning it doesn’t exist as an actual object, and components are pure data containers. Logic is moved into systems and systems match on entities with specified components. All update logic resides in them which makes them highly parallelizable. Just like in OCM, there is no one standard way to define an ECS model and there are many different flavors of it.24
By far the biggest advantage of such object organization that everyone seems to mention first is the performance and memory efficiency: “taking advantage of CPU architecture, structuring data in a tightly-packed way to benefit from its locality in access patterns, and using those access patterns to parallelize as much logic as feasibly possible”.52 ECS also solves initialization and update order issues that are common in OCM.24
Unfortunately, it is not all rainbows and unicorns and one shouldn’t be too hasty putting all his eggs in this basket. “Because systems have explicit signatures, it’s hard to derive or extend them for custom logic”.24 This means that if later in the development a new type of entity needs to be added that acts almost the same as some other entity, it won’t be easy to manage it in the same system, and the solution to this would be to create tag components that only serve to specify logic type. But the problem is that a system now needs to internally branch to handle all types of logic for a component signature, and internal branching in loops that run 60 times per second is opposite of being cache-friendly and defeats the whole purpose of ECS. Alternatively, a new system can be made to match that entity, but it will have almost identical code and ECS will not be able to parallelize it because components being queried are the same. Additionally, most ECSs (but not all) limit 1 type of component per entity which cripples the spatial hierarchy of entities in a game world. For example, in an RPG game where a character is composed of separate customizable body parts, each with a transform component, the component type limitation forces a character to comprise 5 entities.
Another downside is that although ECS is performant “by default” because of cache-friendliness (components of the same type are stored in a single array), it is not always possible for systems to leverage this feature to the fullest in AAA games with massive worlds. Is there a guarantee that thousands of components will be in one contiguous array, considering their size? What is being parallelized in systems that only match on a single component such as player movement, progression system, achievements, etc.? Certain game features go against the grain of ECS altogether, like hand-designed level playthrough, individual interaction or specific VFX emitters firing on a manually defined schedule.54
Lastly, generalized ECS systems do not correlate to fun gameplay. Very often developers who prioritize creating meticulously general systems end up having games that resemble simulations in which gameplay is “I have a character that moves around”.54 There are many nuances to ECS that are often overlooked because the premise of this model is way too appealing, and developers tend to forget that an actual game is not just a tech demo. Ultimately, to truly leverage this model, one needs to answer “Is the performance coming from ECS or from doing the sensible things with your data?”24
2.2.2.4. Composite model
Of course, neither OCM nor ECS is mutually exclusive and both models can be combined in a single game, serving merely as a guideline rather than being an absolute dogma. A custom engine that Bobby Anguelov has been working on aims to combine the best of OCM and ECS. Being ECS at the core, entities are objects with GUID that contain an array of components and systems, while not limiting the number of components of the same type. Components are similar to those in OCM which act as data containers with logic, but which cannot have init or update functions, nor can reference other components or entities. Components can inherit other components. Neither entities nor components can update, because update logic lives in systems which are split into 2 types:
- Local: Per-Entity update, runs first. Entity update is simply the update of its local systems.
- Global: Per-World update, runs second. Reminiscent of ECS systems which manage world state and perform cross-entity transfers. For more information about both OCM and ECS check his amazing presentation.24
Now that we have a proper understanding of both an engine architecture and a game world model, we can finally take a look at some of the existing game engines and analyze their 1) architecture, 2) game world model, 3) portability, 4) versatility, 5) graphics and 6) community.
2.2.3. Raylib
Raylib is not a game engine in a typical sense, rather it describes itself as “a programming library to enjoy videogames programming”.55 It is used not only for game development, but also to create new engines on top of it or any graphical/visualization applications. Raylib’s main language is C, but there are more than 70 bindings to other languages such as C#, Lisp, Go, Python and the list goes on. Target platforms include all major desktops, Android, Web and ARM-based devices like Raspberry Pi. This framework is relatively simple and easy to learn: 558 functions and 34 data types; only ~10% of its functions deal with data pointers; more than 140 code examples. There is no standard API documentation so the main way to learn it is by reading a cheatsheet that briefly describes the usage of each function, or by reading plentiful code examples. Although some might argue that such approach is not beginner-friendly, I would parry by saying that learning the very fundamental principles of game development requires you to be comfortable reading the code and the documentation.

But how is the architecture structured here, you might ask, inquisitive reader, and how similar is it to RTEA? Raylib is broken down into 7 self-contained main modules, visual representation of which is depicted above, and each module is organized according to its primary functionality. The modules are as follows:
rcore- window creation and management, setting up and populating graphic context, shader management, files management (file system operations, compress and decompress files), input handling, camera management and other smaller utility functions;rlgl- graphic API wrapper and pseudo-OpenGL 1.1 translation layer, that contains all OpenGL API calls. This module works as an abstraction layer for multiple versions of OpenGL: 1.1, 2.1, 3.3 Core, 4.3 Core, ES 2.0;rtextures- texture/image loading, generation and manipulation and drawing. 15 different file formats are supported;rtext- font data loading and text drawing;rshapes- basic 2D shapes drawing functions (pixel, line, circle, polygon, spline) as well as shape’s collision detection;rmodels- loading and drawing of 3D models or basic 3D shapes, their materials, animations and collision detection;raudio- audio device management and sound/music loading and playing.
Apart from 7 main modules, raylib also provides extra modules that expand engine capabilities. They are designed to be as decoupled as possible from other modules and therefore can be used as standalone libraries in other projects. The extra modules are:
raymath- math functions to work with Vector2, Vector3, Matrix and Quaternions. Compiled with raylib by default;rcamera- basic camera system with support for multiple camera modes (free, 1st person, 3rd person, custom). Compiled with raylib by default;rgestures- gesture detection and processing (Tap, Swipe, Drag, Pinch) based on touch or mouse input events. Compiled with raylib by default;raygui- a minimalistic immediate-mode-gui library that can be used for all sorts of tools development.rres- a file format designed to package game assets (images, fonts, text, audio, models etc.) into a self-contained comprehensive format that is efficient to read and write to.
The most subtle difference between the architecture of raylib and RTEA is that raylib’s rcore module unites COR (Core Systems) and PLA (Platform Independent Layer) by doing conditional defines based on a relatively small number of target platforms, as well as including HID (Human Interface Device) module. What is LLR (Low-level renderer) in RTEA, in raylib is being split into 5 parts: a graphics device interface rlgl and 4 specialized modules that communicate with it - rtextures, rtext, rshapes and rmodels, with last one also implementing the functionality of SKA (Skeletal animation). RES (Resources) module from RTEA instead of being a single place responsible for resource management, in raylib is split between aforementioned 4 specialized modules, as well as PHY (Collision and Physics). Such approach greatly facilitates modularity of an engine, but when a game grows larger, this separation might become harmful because there are increasingly more places to keep track of where memory allocations and de-allocations are happening. RTEA’s FES (Front End) and AUD (Audio) are raygui and raudio respectively. Last point to note about architecture is that raylib relies on a number of external libraries to load specific file formats of images, fonts, audio and 3D models. SDK module implies that any external library should pass through PLA to provide a unified interface for all other engine modules, however in here only OpenGL follows this convention, while every other external library is used inside modules directly, bypassing PLA.
Raylib does not enforce any particular game world model and there are no real game objects, only intermediary types that are being passed to functions, and functions either draw something on screen or perform user-specified logic - a proper representation of a Procedural model. This approach is what allows this engine to be highly modular. In fact, not only modules from extra can be used as standalone libraries, but also rlgl and raudio. This modularity, as well as an excellent documentation are the main reasons why raylib is such a magnificent learning tool - developers can pick out and swap any part of this framework without worrying that it will affect other components. However, the biggest drawback of this approach is that thinking about a game in terms of procedures is not very productive when it starts to scale up, and to combat this, one would need to implement an actual game world model, either from scratch or by importing an external solution.
Portability of raylib does not come close to Unity’s level - no support for iOS, nor for modern consoles (we mentioned why open source engines cannot support consoles in Section 2.1.3). However, in theory certain modules of raylib can be reused, in which case they would be viewed as third party tools in another engine, rather than being an engine on its own. Nonetheless, it supports both Desktop and Android platforms which covers the biggest chunk of the game market. The versatility and graphics are probably the weakest aspect which is directly correlated with raylib’s philosophy of being simple and easy to learn. By limiting the amount of possible features, as well as using an outdated but simpler graphics API, it lowers the skill floor for beginner game developers. Community, on the other hand, is the strongest suite - bindings to other languages, unofficial ports to other platforms such as iOS and countless open source hobby projects that use raylib at their core and showcase the extents of its power.
Overall, the purpose of Raylib appears to be explaining the basic components of video games and how they are interacting, as well as to teach C programming by making games. Ramon Santamaria, Raylib’s author states that “…many hours have been put into the API design; thinking about the best name for every function, the minimum number of parameters required, the right name of each parameter, the data types structure and more”.55 This is undoubtably showing when reading the documentation - every design choice is explained in exhaustive details, from syntax analysis to expounding which particular functionality is being imported from external libraries. It is also worth pointing out that all external libraries are under permissive licenses which allows raylib to be used on commercial projects without any legal obligations.
2.2.4 SDL. and graphics APIs
As we have observed in raylib’s architecture, most of its modules can be united under the umbrella of LLR (Low-level renderer), which would rightfully suggest that raylib is simply a rendering engine. Anyone who has ever indulged in graphics programming must certainly have heard about SDL, a framework used for a similar purpose. But in order to fully grasp the difference between the two, and potentially between other engines, we first need to have at least a rudimentary grasp of what is OpenGL and how to use it. Modern graphics APIs like Vulkan, DirectX12, Metal and WebGPU greatly differ from OpenGL, and there are numerous books that cover this topic, but what is important right now is that OpenGL is a more simple legacy API that hides many under-the-hood details about a GPU device.
Reddit user u/amdreallyfast explains in plain language a short history of OpenGL and libraries around it. OpenGL started at the time when video cards were rare and there was a need to interface different hardware drivers. At the time, C-style programming was well established and in order to connect OpenGL functions with different drivers, Khronos group decided to use function pointers. To connect function pointers such as glViewport() or glGenBuffers() with a library that defines what those functions do and how they talk to operating system’s video card driver one needs to initialize OpenGL “context” - to run some prior code that will connect function pointers. One such context initializing library is GLEW (OpenGL Extension Wrangler). Other people devised the idea of an event-driven loop with user-registered functions. An example of this is GLUT (OpenGL Utility Toolkit) - it creates a window and registers certain event functions (update, input, draw, idle, etc.) by passing a function pointer, and calling it when the appropriate event occurs. But as time has passed and OpenGL versions had evolved, others made their own window management/event loop APIs: FreeGlut (window management), GLLoad (OpenGL state initializer) and GLFW (state initializer + window management). All of them operate on a C-style paradigm of function pointers. Then GUI framework Qt decided to make everything from scratch: window management, event loops, and OpenGL context initialization in a single OOP package.56 One additional piece that an author forgot to mention is that for any version of OpenGL older than 1.1, additional loader library is required to override the original gl.h with the one of a newer version. The most popular one is glad - it allows generating files with a specified version and include extensions of choice.
Raylib relies on GLFW for context initialization and window/input management, but SDL implements this functionality internally because it uses a combination of OpenGL and Direct3D. SDL provides a more fine-grained control (file IO, multithreading, timers, CPU detection, power management status) over the target platform compared to raylib. “Raylib provides some higher-level functionality and takes multiple decisions for the user to simplify API usage”.57 A comparison of code complexity between the two is demonstrated below:
SDL2: Window and renderer initialization/deinitialization (modern OpenGL)
// Initialize SDL internal global state
;
// Init window
SDL_Window *window = ;
// Init OpenGL context
SDL_GLContext glcontext = ;
// App loop
while
// Deinitialize OpenGL context and window
;
// Deinitialize SDL internal global state
;
raylib: Window and renderer initialization/deinitialization (modern OpenGL)
// Init raylib internal global state and create window
;
// App loop...
while
// Deinitialize raylib internal global state and window
;
Architecture-wise, SDL consists of a main library focused on system functionality and some satellite libraries meant to be useful but optional like image loading, font loading and text generation, managing audio devices or networking functionality. There are around 700 source code files organized by systems, platforms and backends, therefore a build system is much more complex than of raylib, and it is designed to be dynamically linked (raylib supports both static and dynamic linking). Unlike raylib, most functions accept references and return error codes to check if they worked as expected. SDL is backward-compatible as deprecated functions are kept in the library, while raylib does not care about backward-compatibility.57 Viewing it through a prism of RTEA, it nicely fits into PLA module as well as bare minimum of LLR, which can further extended with satellite libraries. Raylib’s approach is to use glfw, which is a pure PLA module, and to implement COR and LLR on top of it.
Neither of those frameworks provides any dedicated game world models by default, as both are written in C and focus on lower-level aspects. Official target platforms for SDL include the same as for raylib as well as iOS, meaning that support for Xbox and PlayStation is not provided by default58, but many game development teams have internally adopted it to console SDKs. In terms of versatility, raylib holds an upper hand, supporting 3d meshes, materials and animations loading for several 3d formats, providing more functions to render geometry shapes, ability to generate and manipulate images, and providing an embedded font so that users can draw text by default. However, SDL provides “raw” data from input events directly to the user, giving him more power how to manage them with a cost of additional complexity. SDL produces higher quality fonts by relying on heavy but powerful FreeType2 and Harfbuzz libraries. SDL includes a module for networking while raylib has no networking support. Both SDL and raylib allow loading and playing static and dynamic (streaming) audio data and manage the audio device. When it comes to graphics, it all depends on the developer’s expertise first and foremost, however SDL has a support for Vulkan and Metal APIs.58 Because SDL has been around for more than 20 years and battle-tested in many professional products, there are a lot of examples on how to use it, but in my experience many of them are outdated and have in mind that users are using dated technologies. Raylib, on the other hand, is roughly 10 years old and because most of its user-base are students and hobbyist, there are a lot more of fresh learning materials. Most importantly, while raylib can fit into the definition of a game engine, SDL on the other hand can be hardly called so as its main purpose is to provide low level access to audio, input devices and graphics hardware.
2.2.5. Bevy
Bevy is a young and unorthodox game engine written in Rust, and it approaches game development in a rather radical way by adhering to ECS world model through and through. To understand why certain design choices were made, we need to understand Bevy’s philosophy which Carter Anderson, its original author, shared on bevy’s repository discussion page. First incentive, which I fondly support, is to be free and open source:
Games are a huge part of our culture and humanity is investing millions of hours into the development of games. Why are we (as game developers / engine developers) continuing to build up the ecosystems of closed-source monopolies that take cuts of our sales and deny us visibility into the tech we use daily?47
Second point is productivity, which is manifested in multiple ways: fast build/run/test loop, for which either a scripting language or a native language with fast compile times is required; using the same language for game development as the engine; and simplicity, being easy to use for common tasks without hiding a lot of lower-level details. Next important point is a world editor for scene management, which is absent from bevy because it is optional in Anderson’s opinion. Lastly, an engine needs to be data-oriented to help a game run faster due to cache-friendliness and ease of parallelization, and to trivialize managing game states.47
Bevy game is called App, and it consists of 3 fields: World stores all game’s data, Schedule holds the systems that operate on this data and Runner controls the execution strategy of those systems. Perhaps the biggest feat of this engine is how brilliantly it tackles modularity. All engine features are implemented as plugins - collections of code that modify an App. Internal modules like the renderer or input handler as well as complete games are all implemented as plugins. This versatility allows game developers to only pick the features they want and replace any components they do not like. DefaultPlugins - a collection of 31 plugins that contains core engine features typically expected from a modern engine like rendering, asset loading, a UI system, windows and input.59 This approach makes it challenging to compare bevy’s architecture with Gregory’s RTEA because instead having a clear dependency hierarchy of engine’s components, every plugin acts as an independent block that can be added into a flat list of dependencies. Additionally, plugins themselves are quite small, and their functionality is pretty narrow. Overall, default plugins provide a bit of everything that RTEA’s architecture requires: basic PLA, COR, well-pronounced RES, renderer modules, primitive animations, AUD and even GMP.
Bevy has its own implementation of ECS model that encourages to break down game objects into the tiniest components. For example, a person entity can consist of a tag component Person and a Name components which is a struct with a string field, which then is queried like this Query<&Name, With<Person>>, meaning “iterate over every Name component for entities that also have a Person component”. To represent globally unique data such as time or asset collections, bevy uses Resource - a type that can be inserted into a World as a singleton. Entities, components and resources are stored in a World - a data structure similar to a hash table that allows to perform insert, read, update and remove operations. Systems that perform structural changes to the World are called Commands - they cannot parallelized because they need to have mutable access to the data, which Rust compiler forbids and only allows one mutable or several immutable references. In order for systems to communicate with each other and share some data, bevy uses Events. Events can be sent using the system parameter EventWriter and received with EventReader on the next frame. Otherwise, to send an event immediately there are Triggers, which implement the observer pattern, and can trigger other Triggers which will all be evaluated at the same time. To get a better understanding on how it all looks in action, take a look at one of bevy’s examples: https://github.com/bevyengine/bevy/blob/main/examples/ecs/ecs_guide.rs.
Hytale’s developers assure that despite being challenging to reason about at first, ECS can provide powerful game development tools.52 Although there are many benefits of this model, it is important not to forget possible pitfalls that Anguelov has introduced to us previously. Moreover, LogLog Games developer has come to the conclusion that many problems do not disappear even after gaining great proficiency with this model. “ECS is a tool, a very specific tool that solves very specific problems, and that does not come for free”.54 Another problem is that while for many engines ECS is an optional library that can be used or not, in Bevy the whole game is ECS and ECS only. Implementing UI widgets while being restricted by this paradigm is counterproductive, one can even say “completely insane”. Considering that systems are parallelized and do not maintain consistent ordering across frames, one should specify a constraint on the order of execution to maintain consistency. But “for any non-trivial game what ended up happening is the user ends up specifying a ton of dependencies anyway, because things in a game tend to need to happen in a specific order”.54
Bevy’s platform support is similar to SDL’s: Windows, MacOS, Linux, Web, iOS and Android. Versatility is too early to judge because this engine is still in the early stages of development and some important features are missing. Documentation is sparse. Approximately every 3 months a new version is being released that contains breaking changes to the API. Graphics are promising despite the rendering engine being in an extremely early stage, and wgpu - bevy’s underlying graphics API - is based on WebGPU standard which runs natively on Vulkan, Metal, DirectX12, and OpenGL. Contributing back and code reuse is deeply tight into bevy’s philosophy and is greatly encouraged. Tools for this engine as well as complete games are created as plugins that can be easily integrated into a new project. This speeds up the process of writing boilerplate code and simplifies the procedure of getting started. Unsurprisingly with this approach, the community is beyond lively, and an official page with community assets lists around 500 complete examples.
Bevy is not trying to out-compete other open source game engines. As much as possible we should be collaborating and building common foundations. Bevy is already benefitting massively from the efforts of the Rust gamedev ecosystem and we would love to pay it forward in whatever way we can.47
As it stands now, Bevy is the head representative of Rust game development and arguably the best place to learn and practice ECS. A recent game that was created with bevy is called Tiny Glade, which demonstrates the extents of this engine. The biggest lesson to take away here is that the concept of describing a game as a collection of granular plugins is very powerful and allows for superb modularity, but the questions persists whether this level of modularity is deeply tight to ECS or can be achieved by other means.
2.2.6. Godot
Easily the most popular open source game engine that has gained a lot of attention in recent years is Godot. At the time of writing, it has 87.4k stars and more than 2.5k contributors on GitHub. It describes itself as “a feature-packed, cross-platform game engine to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so that users can focus on making games without having to reinvent the wheel”.22 Honestly, this description appears to be rather broad and can be applied to any engines out there, but the key points are “a set of common tools” and “without reinventing the wheel”. Unlike most of the new engines/frameworks out there, including raylib and bevy, that lavishly encourage developers to reinvent all kinds of wheels, Godot’s purpose, on the other hand, is to create a game in the fewest amount of steps possible.
Although Unity’s aim is seemingly the same - to provide a set of tools so that game developers can make a game fast, its approach to this problem is opposite of Godot’s. Unity strives to be a general-purpose engine that Toftedahl and Engström describe in their Taxonomy by providing virtually any feature game developers might ever need, while Godot “intentionally does not include features that can be implemented by add-ons unless they are used very often”.22 Instead, some core functionality is moved to officially supported add-ons, that can be imported to a new project with a click of a button. By doing this, project maintainers have a smaller and cleaner code base to work with, and users have easier time contributing - less information to learn and less time compiling. Of course this also means that 3D workspace tools are kept at medium and things like terrain editor or complex skeletal animation tools will need to be imported as plugins.
We skip comparing Godot’s architecture with RTEA because Ullmann and colleagues have already done it for us and found all 16 out of 16 subsystems present, including a world editor (EDI).11 In fact a world editor is implemented so impressively that even bevy’s creator can hardly help but to admire it47, so we have no right taking a detour around it. In essence, a Godot editor is a game that runs on the Godot engine. There is a built-in code editor and many other features present in most of the engines’ editors, but what is a fairly novel strategy is that Godot uses its own user interface toolkit. This means that users use the same code and scenes both to build games and to build plugins to extend the editor (without reloading the editor). This practice of using its own tool is called “eating your own dog food” which serves as a quality control for UI toolkit, because “editor itself is one of the most complex users of Godot’s UI system”.22 Another feat of the editor is having an experimental support for Android and web browsers, which means that users can work on a game from virtually anywhere.
Godot is written in C++ and for scripting it uses its own scripting language GDScript, designed specifically for the needs of game developers and game designers. It is also optimized for gameplay code with built-in types like Vectors and Colors and easy support for multithreading. But GDScript is not the only possible choice, there is support for C# with .NET as well other languages like C, C++, Rust, Swift and others via GDExtension.
One last thing to keep in mind about the architecture is the use of Servers to provide multithreading capabilities. Most engines use job scheduling technique for concurrency, but it is a rather complex approach that sacrifice ease of use as it does not protect the code that is being modified in a separate thread, so users need to manually manage mutexes or semaphores. Servers solve this problem by not requiring threads to sync by the end of each frame - a Server with Logic and Physics can run on a current frame while Rendering can be processed a frame later.60 By taking most of the responsibilities of concurrency on itself, users have easier time writing multithreaded code, however this tradeoff can potentially cause one-frame-off lags.
For the game world model, instead of ECS, Godot uses OCM and makes heavy use of inheritance (data-oriented optimizations are still present for physics, rendering, audio, etc., but they are separate systems and completely isolated). Original authors came to the conclusion that this leads to better usability for users while still being performant in most use cases: “Inheritance is more explicit - what would be implicit relationships between components in ECS, are now explicit in the inheritance chain. This makes it very easy to understand how the scene nodes are organized and what they can do, by just looking at the inheritance tree”.61
The smallest building block of a game is called Node and other game objects inherit from it, akin to Unreal’s CoreUObject. It contains both data and logic. One or more Nodes can form a Scene. A Scene can be a character, a weapon, a menu or an entire level. It works the exact same way as a class in pure code, except that it can be designed both in the editor and in the code. “Thanks to everything being nodes (and not entities with components) it becomes easier to reuse and combine everything as much as possible - Godot does not distinguish between scenes and prefabs. Scene is simply a bunch of nodes forming a tree, which are saved in a text file. Scenes can be instantiated and inherited”.61 When some event occurs to a Node (e.g. objects collided, something needs to be repainted, button was pressed, etc.), it can emit a Signal to send information to other Nodes. This feature allows them to communicate without being hard-wired in code. In Godot’s game world model, Nodes are just interfaces to the actual data being processed inside Servers, while in ECS the systems process entities (data) directly.61
If Node is a base building block of a game then Object is a base building block of the engine - all other classes inherit from Object, including Node. A custom Node can be derived from Object with new properties, methods or signals which can drastically change the organization of a game. Another important class is Variant, which is a container that can store almost any engine data type inside of it. This is what allows GDScript to be dynamically typed, and its main purpose is to communicate, edit and move data around, rater then to store it persistently.22
A list of supported target platforms is standard - Windows, Linux and MacOS desktops, Android, iOS and web. An achievement worth mentioning a second time is that an editor also runs on Android and Web browsers, not just on desktop. It is quite featurefull and includes a code editor, an animation editor, a tilemap editor, a shader editor, a debugger, a profiler, and more. Godot also allows creating non-game applications thanks to the built-in UI system that can replace other toolkits like Qt, GTK or Electron. The quality of graphics is obviously hardware dependent, but the engine supports 3 rendering methods with varying degree of graphics options diversity: Forward+ will use Vulkan API with all features, Forward Mobile - is slightly handicapped version of former to allow drawing simple scenes faster, and Compatibility will use OpenGL backend which is more suitable for low-end devices.
As a culmination of good design decisions, Godot’s community is flourishing like no other and despite being much younger than Unity or Unreal, can already compete with them in terms of user-generated tutorials and free assets. Asset store hosts more than 3k officially supported plugins that either extend the editor’s functionality, or contain entire demo projects, all of which are free to use. “Godot is made by its community, for the community, and for all game creators out there”.61 Whenever users need a new feature to be merged into the engine’s core, open discussions take place to decide whether a particular addition will benefit the most users first. This openness to public prevents adding features that benefit only the corporate greed of shareholders like “Runtime Fee” in Unity.36
Overall, Godot is the most pleasant engine that I had to work with. It is simple to learn and simple to use. Both the documentation and the API reference are incredibly informative without being too overwhelming, both of which can be accessed within the editor. To conclude, here is what Juan Linietsky, Godot’s original developer, writes about his vision for the engine:
Godot as an engine tries to take the burden of processing away from the user, and instead places the focus on deciding what to do in case of an event. This ensures users have to optimize less in order to write a lot of the game code, and is part of the vision that Godot tries to convey on what should constitute an easy to use game engine.61
2.2.7. Game modding
Ultimately, when talking about long term success of a game, we cannot overlook the importance of modding, as this is what allows a game to avoid stagnation and stay alive without requiring much of developers’ time. There are numerous factors to consider whether adding modding tools is a good idea or not, but it is something to be aware of nonetheless, especially when we talk about the relationship between a game and its engine.
As Gregory mentioned, Game-Specific Subsystems is where a game starts to be distinct from the engine, and those subsystems are implemented on top of Gameplay Foundations (GMP) module by gameplay programmers and designers. Because GMP already outlines a game’s genre, how a game world should be structured and how game objects inside it should be managed, further development process is reminiscent of game modding - adding new content either in a form of game objects, or in a form of logic to those objects. Conceptually speaking, this turns a game into a special-purpose game engine as per “Taxonomy of game engine”15, which might be frightening to some studios because of the high risk of violation of intellectual property rights. The best example of this occurrence is how Dota was born as a Warcraft 3 mod over which Blizzard had no legal rights.62 Yet despite this minor inconvenience, modding usually results in a net benefit for game development studios, as it ensures that they have a clear understanding of the desires and needs of the player base. For instance, in the game Elden Ring, a popular mod “Seamless Co-op” has made a game director Hidetaka Miyazaki consider whether they want to implement a start-to-finish co-op experience in their future games.63
So what traits should a game have in order to achieve modding success? We can find the answer in Lufa’s work “Modding Heaven: When Games Become Engines”.64 He discerns three major characteristics:
- Support - how much modding support is built into a game; do developers provide any tools for this?
- Nature - sandbox or open world versus fixed path games? How suitable is the game’s environment to a new and experimental content?
- Passion - are gamers passionate about a game to create new content or fixes for it? Even unmoddable games can still be reverse engineered (Dark Souls or Minecraft) if players like them enough.
A game can reach “Modding Heaven” even when not all traits are present. Original Doom, for example, was designed to be modded and reused, and community was passionate to work on it even despite the nature of the game being quite linear and limiting. Even 30 years later the community is still very active, producing staggering variations of the game, from boxing to a lawn mower simulator, from a trench warfare to an RPG fantasy. Minecraft on the other hand has an excellent nature - simple game progression inside an infinite and random world that makes it easy to place new content without conflicts. Even despite the developers not providing any official modding tools, players became engaged enough to produce all kinds of modifications.
But the most successful moddable game is Skyrim. It has got all three traits which had ascended a game to “Modding Heaven”. From the very inception it was planned to be shipped with modding tools in a shape of a Creation kit - the exact same instrument used by Bethesda developers to build it. Open world RPG design favors exploration and do not enforce a fixed progression path. Huge world makes it possible to add new assets without conflicts. Nevertheless, it was also lucky to come out at the right time to get a lot of attention from fans of Game of Thrones and Lord of the Rings. As a result, it is currently the most popular game on Nexus Mods (website to share game mods) with more than 5 billion downloads and 94 thousand mods. It is possible to create completely new experiences to such extent that even small indie studios make Skyrim based games and writers use it to create interactive stories that win Writers’ Guild award, simply by making a mod with an interesting story.65 Reddit user u/Capital-Feed-3968 demonstrates the power of Skyrim modding in a single picture titled “I don’t know what game I’m playing anymore”. 
Lufa concludes with a hypothesis that large modding scenes might be the result of content vacuum, and that a game can only achieve a “Modding heaven” if its vanilla base is broken. It is a plausible assumption considering that both Skyrim and Minecraft were rather dull and buggy when first released, but Terraria, despite standing very close to Minecraft in all 3 points, is not in “Modding Heaven”. Unlike Minecraft, Terraria’s base game is packed with content, has a smooth gameplay, and mods there do not create brand-new experiences but only extend the existing game.
Game development companies are aware of the importance of user-generated content. This is why CD Projekt Red has released REDkit editor for Witcher 3 which allows users to create new experiences and modify all aspects of the base game using “refurbished versions of the same tools which were used by the RED developers”.66 Paradox studio’s engine for Hearts of Iron has been designed to be used by both game designers and modders alike: “We want to put as much power as we can into the hands of the people who are making content. They shouldn’t have to ask a coder for help”.48 Creators of GenieLabs have a similar stance and believe that it is easier to allow players to create game content by themselves rather than spending their budget on a new DLC.33 Epic Games take one step forward and introduce monetary compensations for people who create popular “islands” using Unreal Editor for Fortnite.39 And let us not even start with games like Roblox, Rec Room and Garry’s Mod that act as special-purpose engines and rely on players to create actual gameplay.
To sum it up, game modding is very important and often overlooked. It can significantly extend a game’s lifespan, but only if it has the right nature and has managed to get the attention of the right audience. Players can create new experiences on top of a base game, with the downside being that developers do not get to decide what the community should work on. Especially if the game is a multiplayer, and developers host servers it can quickly become a charity. However, they should not get discouraged because in case of success, those developers gain a loyal community and achieve a positive brand recognition.
2.2.8. Takeaways
To conclude this section, here are four key observations and their consequences:
- It is meaningless trying to draw a line between a game and its engine (ANENLOCO-2) since a game can become its very own engine with the help of modding tools.
Certain projects like Roblox and Unreal Editor for Fortnite make the process of game development an actual gameplay. Furthermore, by knowing that a genre manifests itself in the functionality provided by GMP module and concrete implementations of Game-Specific subsystems, we can further elaborate ANENLOCO-3: not only the games of different genre can be produced within the same engine, but different genres can live in a single game (or rather in a single game world).
One conceivable implication of this inference is that video game distributors like Steam or Epic Store might morph into an application with the gameplay and sell games as add-ons for their game worlds. The benefit of this for game developers is that potential buyers are more likely to stumble and try out the game’s demo as there is less overhead between players and the game.
- Open-source game engines tend to focus on production phase problems.
Problems at that phase account for 45.27% of all game development problems, while at pre-production stage the percentage drops to 39.18%.2 This is still a sizable chunk which includes requirements specifications, game design documentation, project management, prototyping, validation and verification, and of course asset creation in third party software.8
The reason for this negligence was already hinted in 3 when they found out the motivation behind engine developers. They do it for the sake of learning certain tech aspects like rendering, procedural generation, multiplayer, voxels, generalized world interactions, etc. The need to create actual games with them is very often absent. That is why many game engines stay oblivious to those problems - they were irrelevant to their authors.
- Engine architecture can be designed in many different ways.
We have seen how an engine with a Procedural World Model approaches its architecture differently from Gregory’s RTEA. Modules there take more generalist approach which allows them to be both-ways modular: raylib’s raudio, for example can be both plugged out to be replaced by some other audio library, continuing to comprise the same engine, and be imported as a stand-alone audio library into another game engine. Meanwhile, Bevy’s ECS model is only one-way modular - Audio module can be safely replaced with another similar library, but the same module is not designed to be engine-agnostic.
This is what ANENLOCO-1 stresses about - there is no universal way to describe how game engine components should communicate with each other. All available learning resources focus on the implementation of those components at the lowest level. This lack of universal Game System Description Language2 is of prime concern and should be addressed sooner rather than later.
This issue is further exacerbated by the fact that game engines, especially older ones, act like a Ship of Theseus - not all components age at the same speed, and many parts are being replaced with another, while continuing to comprise the same engine. “Even the ubiquitous Unreal Engine 4 is still built on a foundation that started with the first Unreal, which came out in 1998”.20 To ensure that one component can be safely switched with another, one needs to clearly define inputs and outputs of that component.
A reasonable solution would be to approach this issue similarly to communication protocols like XMPP or IRC for messaging, or Wayland for display clients communication. Designing and ratifying game engine specifications is certainly not a trivial task, but it ought to reap the benefits in the long term. The protocol is language agnostic and only describes the engine systems at a high level. Building a game engine on top of a protocol and using third-party libraries that implement that protocol would significantly help with managing the dependency tree, as well as with the future extension of the engine feature set, which consequentially improves modding capabilities of games built with that engine.
- Engine flexibility is reciprocal of a game’s certainty.
A visual relation between the two is shown below and is essentially a hyperbolic function. On one end of a spectrum there are “Open world voxel-based games”, as an example. They can be created with virtually any kind of software tools and leave a lot of room for creativity for developers. Thus, an engine for this kind of game is extremely flexible and can take any shape because the game does not require anything specific from it. On the other end of the spectrum there are special-purpose engines and game mods that create a new experience atop of the base game, like Warcraft 3 as the engine for Dota, or Arma 3 as the engine for DayZ and PlayerUnknown’s Battle Royale. Having less flexibility implies that there are a lot of constraints imposed on the gameplay, but those constraints act as guidelines for game designers or gameplay programmers, leaving no room for ambiguity and dictating the development direction. Games like this tend to be modding friendly and easy to expand at the cost of being, well, inflexible.
2.3. Programming Languages Analysis
In the beginning of this paper we stated that it is crucial to periodically evaluate how well the development tools satisfy state-of-the-art game development needs. We have more or less broken down which set of features and components make up a pleasant to use, yet productive game engine, and now we need to pick the appropriate foundation for building such an engine. This section examines various programming languages employed in game engines and evaluates their strengths, limitations, and suitability for different aspects of engine development.
2.3.1. Requirements
2.3.1.1. Abstraction
Before we take a look at any specific language, let us first have a clear understanding of the current trends in the game development programming, as well as in regular software engineering, and see if there is a space for any improvements. A worthwhile observation that Anderson and colleagues had made is that the progress in programming languages and tools around them is very often characterized with the increase in abstraction level, or in other words “the conceptual size of software designers building blocks”.6 This means that the more modern a tool or a language is, the lesser the amount of moving parts there are for developers to learn, which makes them easier to learn and use, causing any new projects made with them to be developed significantly quicker compared to those made with a tool or a language from a previous generation. However, the tradeoff for lowering the skill floor is that programmers are being further separated from the underlying systems and are given less options to manage a program’s execution strategy. Regarding this problem, Angelo Pesce writes:
The art of programming close to the machine is disappearing… it’s the silliness of divorcing programming from the craft of processing data. Of having built entire engineering practices, languages, systems, that created an unmanageable amount of complexity for no good reason. And then to add insult to injury, layering on top more tools in the foolish errand of trying to solve complexity with complexity… The average big user-facing computing thing (program, website, game…) is a monster so big that nobody understands it end-to-end.19
One such culprit who solves complexity with more complexity is Unity with its Common Language Runtime (CLR). CLR makes sure that game’s logic that is written as C# scripts will be working the same way regardless of the target platform, but it leaves game developers oblivious to the lower-level systems, and gives them very little control over game’s specifics on different targets.
The problem with this kind of abstraction is how challenging it is to reorganize the engine’s structure to accommodate certain needs of the game. On the other hand, Bevy has a much saner approach to abstraction - not only games are written in the same language as the engine, they are the extensions of bevy, and every gameplay function call can be tracked to the origin, meaning developers can make their own abstractions and not rely on the engine’s defaults. The point here is that we should aim at avoiding needles structural complexity, because as Pesce writes, there are rarely sufficiently adequate reasons for such complexity, and this is very often a result of cargo cult and writing whatever is popular at a time.19
2.3.1.2. Object-Orientation
“A game’s world model is intimately related to a software object model provided by a programming language, and this software model ultimately pervades the entire engine” (chpt 1.6.15.1)10. A very common form of abstraction is treating everything as an object, aka OOP programming. OOP is the backbone of Object-Component game world model, and it is used extensively in the industry, but an important factor to take into consideration whether to include OOP features or not is the primary target platform. Zhang et al. have researched how Object-Orientation affects the performance and executable file size on mobile devices and concluded that “OOP should be used with great care in the development of mobile games, and that structural programming can be a very competitive alternative”. Structural programming presumably refers to procedural programming, or any paradigm that abolishes the use of objects and instead pivots around program’s control flow. The results of structural optimization on OOP code is the decrease of file size by 71%, decrease in lines of code by 59%, and decrease in loading times from 16% to 34%. However, the performance loss is negligent in modern C++ on desktops, being on average slower by ~1%, although virtual functions might cause ~5% performance loss.67
OOP is not a prerequisite for game development, and entities can be represented as just data. If a game requires 100 different types of monsters, it does not mean that an engine needs to have a generic monster class and 100 different subclasses. It can just as well be a base monster struct with 100 sets of parameters. Nonetheless, this programming paradigm has been in existence substantially long for a reason and is unlikely to disappear any time soon, thus we need to make sure that a language we choose accommodates OOP features. But what are those OOP features, and what even is an object? Peter Wegner summarizes them as follows: “Objects are collections of operations that share a state”, and Tim Rentsch further adds that they are “generally opaque to the outside”.67 Importantly, “object” is an abstract term, so anything that has a state and some methods on it can be an object. This is it. Optionally, but not fundamentally, a language can provide prototypes, subtyping (polymorphism), encapsulation and inheritance, states Alan Kay, a pioneer of object-oriented programming.68
2.3.1.3. Speed
The difference between software and game development is that games are all about speed, while software gives more emphasis on scalability, maintenance and safety.26 More specifically, speed is important in 3 different ways:
- Game’s execution speed - how fast each frame is calculated.
- Short-term development speed - how fast a new feature can be integrated into the project.
- Long-term development speed - how quickly or easily a code can be understood over the project’s lifetime.
Last point concerns the game’s architecture rather than it’s programming language, and since we have already covered this topic, in this section we shift our focus towards first two points.
Short-term development speed is characterized by how fast each cycle of build-run-test loop can be performed. To skip a compilation step and keep the game running in order to test new configurations, big projects either include a scripting language, or move certain parts of the game into a dynamic library which can be reloaded after some changes. This in turn allows a game to be written in the same language as the engine. However, in certain situations, primarily at the early stages of development cycle, a game has to be recompiled quite frequently, thus we cannot glance over the language’s compilation speed.
The need for runtime speed is wanted the most because games need to process user input and update the game’s state 60 or more times a second. For this, more often than not, developers need to manually manage the game’s memory, and cannot rely on language’s automatic memory management or a garbage collector. Because game development is more mindful of the hardware19, this is partially why C and C++ have gained such popularity - they give developers close access to the hardware, yet being perfectly readable unlike assembly. C++ is ubiquitous in triple-A game development because it allows to calculate as much as possible as fast as possible.69
Presently, there has been an emergence of new programming languages that attempt to give the similar freedom into the hands of developers, while promising to fix the shortcomings of their predecessors. Instead of reviewing a dozen of them, we are going to assess those that have performed the best at the benchmarks of programming languages and compilers. One such website which provides this kind of benchmarks is programming-language-benchmarks.vercel.app 70, with the latest data being updated on 22nd of January 2025. Certain benchmarks aim to test specific software procedures like caching and indexing, serialization and de-serialization, parsing, multithreading and so forth, but a good place to start looking at them would be a simple “hello world” performance test. The fastest result gives us a Go program (0.6ms) but compiled with a Tinygo compiler, while default one is significantly slower at 1.5 ms. Tinygo is an LLVM frontend, and in fact many compilers on this list use either LLVM or C as the language backend. Zig program runs in 1.0 ms, as does C++ program compiled with GCC, while C++ compiled with Clang slows down to 1.4 ms. Nim, which uses C under the hood runs at 1.0 ms compiled by default, and at 1.2 ms when using Clang. V, another C frontend, runs at 1.0 ms when compiled with Clang without a garbage collector, and 1.4 ms with Clang and a default garbage collector. C shows 1.1 ms time when compiled with zigcc, 1.3 ms with GCC, and 1.5 ms with Clang. Two LLVM frontends, Odin and Rust run at 1.1 ms, and 1.2 ms respectively.
This trend holds for many benchmarks designed around processing large input data and bulk calculations, with occasional appearance of other languages at the top. While all languages that were mentioned are good candidates for writing a game engine, as they aim to be as fast as C, while addressing many of its problems, unfortunately we will not be able to compare them all due to the sheer scope such study requires, and instead we will focus on C and C++ because of their legacy, Rust because it has been gaining a lot of popularity recently, and Zig because of author’s subjective reasons. Nevertheless, they all deserve their own research, especially Odin which is designed specifically for game and graphics development.
2.3.1.4. Programming languages in game development
Research performed by 3 in 2020 has showed ten most popular programming languages on GitHub used for writing game engines. To aid the aim of our paper, we’ve also included each language’s birth year. By the time of writing this paper (5 years later), newer languages have emerged into scene and could push PHP and Lua out of this table.
- C++, 37.94% (1985)
- C, 14.54% (1972)
- C#, 11.70% (2000)
- JavaScript, 9.93% (1995)
- Java, 9.57% (1995)
- Go, 4.96% (2009)
- Python, 4.96% (1991)
- TypeScript, 2.48% (2012)
- Lua, 1.42% (1993)
- PHP, 1.06% (1995)
Possible interpretation of this statistics is:
- C and C++ are the oldest and the most reliable languages. Combined, they overtake other languages by a significant margin.
- C# popularity stems from easy interoperability with Windows desktops, and being used by Unity many developers are exposed to C# as their first game development language.
- JavaScript and TypeScript are currently the go-to choice for web-based games.
- Java is high in the list because of Android development.
2.3.2. C/C++
Although C and C++ are two different beasts in terms of language design, the reason for lumping them together in this section is because they share the same compilers and tooling around them, and it is common to find C projects in C++ codebases. However, it does not necessarily mean that a good C++ programmer is a good C programmer and vice versa.
Key distinctions between C and C++ is that C++ is more lax towards the modernization, and each new standard, which is released every 3 years, dictates new rules. Ricky Senft says that this language manages to conjoin modern concepts with classic software principles.69 C standard committee, on the other hand, puts backwards compatibility above all else.71 Another one is that C++ was born as “C with classes”72 and revolves around Object-Oriented Programming paradigm implementing concepts such as polymorphism, encapsulation and inheritance. On the other hand, C remains more minimalistic relying mostly on Procedural Programming paradigm. It is possible, however, to write OOP code in C, as it is merely a style of programming, but this code will look cumbersome at best with function pointers all over the place.
The reason for popularity of C family of languages in game development is because “…engines must work close to the hardware and manage memory for performance. Low-level, compiled languages allow developers to control fully the hardware and memory”.3 A similar claim has been made by Pedriana from Electronic Arts who stresses on the importance of low-level operations and inability to rely on a language’s automated memory management.17 Considering that C was born as an alternative to assembly language which would help to port Unix operating system to other platforms73, performance was the top factor dictating the language design and specification. Thus, it should not be surprising that earliest game developers had also decided to adopt C precisely for its performance and portability.
The other advantage of using C is how well-established it is. There is an enormous number of libraries as well as learning resources. Most of the modern software infrastructure was built in C and as a result it is now a lingua franca of programming. Code written in C can be used on any operating system or electronic device, and other languages often provide a C ABI to call C code. This is why a lot of utilities used in game development are written in C - to make sure it can be used on the widest number of platforms.
Now let us discuss some of the shortcomings that prevents two languages from being the ideal choice for a game engine. The biggest one has to be the undefined behavior - behavior upon use of an erroneous program construct or erroneous data for which ANSI C Standard imposes no requirements.[79] It is deliberately left holes in the standard that allow compilers to decide how to handle code that would not behave the same on different platforms. As a simple example, consider the following C program:
int
-O is a flag that applies optimizations. Bit shift on length more than type size is considered undefined behavior, thus a compiler is free to optimize it in any way it deems appropriate. This results in different outcomes for debug and release builds. Other more common examples of undefined behavior are null pointer dereferencing and out of bounds array access, which are difficult to detect on spot. Very often undefined behavior will live in the source code until it breaks the program in the worst possible moment. Such moment may arise when switching a target platform, a compiler, a version of compiler or even some compiler flags. To put is simply, undefined behavior is a time bomb.74
Second problem is the complexity of the language. Although not the case for C, which is rather minimalistic with its syntax and semantics except for macros, C++ has a very steep learning curve. If C is a shovel, then C++ is an excavator with all kinds of knobs and handles and even a dashboard. As the language has been evolving over decades, it has incorporated new features and paradigms resulting in a rich but complex feature set. Certain syntax features like operator overloading and templates make it daunting to learn. Although templates are a powerful language construct that allows to perform compile-time computations, mastering them is a challenge.
Third problem addressed at C++ is that STL (Standard Template Library) is not a good choice for game development because of its hidden allocations. STL allocators are unpleasant to work with, cause growth in the program’s lines of code and lead to poor performance. It lacks certain functionality commonly used in game development, like containers that accept nodes and do not perform any allocations, or containers with built-in memory tracking.22 STL code is hard or impossible to debug due to cryptic variable names and void pointers. Most importantly, STL emphasizes correctness over performance17, which we have covered already is not the right approach in game development. A counterargument of “well, don’t use it then” does not apply because standard library is the first and major software library any programmer is exposed to. Having it as a default choice only introduces an overhead of removing it, which is counter-intuitive and counter-productive.
Fourth issue is poor tooling compared to more modern ecosystems. As we have seen already, not only different compilers but even compiler flags might lead to different behavior of the same program. There is no universal build system or package manager - make, cmake, meson, ninja each offer unique capabilities and limitations requiring developers to adopt a new workflow for every project. It hinders the collaboration and code sharing which is essential for any kind of software development. This is why header-only libraries exist in C, because it is easier to include a 15 thousand line file than to build a small library of the same functionality. In 19’s opinion, preference for code reuse with package management over code isolation is the best way to prevent ever-growing complexity.
Lastly, both C and C++ lack type reflection, or in more sophisticated terms Runtime Type Information Inference. There is no built-in way to get an enum variant as a string, or iterate over each member of a class. As an example, a GUI level editor might expose an editable field of a class, but there is no way to get the name of this field, or extending a parent class with additional fields if another class with a certain name is indexed by one of parent’s fields. A common workaround is to use clang compiler and include a hefty libclang library to get this kind of information, or to write some generator scripts to extract specific reflection data. Considering how much burden would be relieved from the shoulders of not only game developers, but developers from other fields, it remains a mystery how this feature is absent from such an elaborate language.
In conclusion, despite evident issues with C and C++, they have stood the test of time and proved to be reliable tool for game development. Even in many decades to come, it is unlikely that those languages will vanish. This is due to feedback loop where developers use C++ for games because this what other games are written in, new developers learn C++ because other game developers use it to write games, which causes even more games/tools to be written in C++. However, it does not mean that other workflows cannot be incorporated into C/C++ ecosystem. One might use python to generate C++ code, use clang static analyzer to check for errors and use formatter to format the code accordingly. Just as the Roman stone road can become a foundation for an asphalt road, C/C++ libraries can become a foundation of projects written in new, better languages.
2.3.3. Rust
While C++ has long been a gold standard, the advent of Rust offers a fresh perspective on how to blend modern language features with safety and efficiency. It was created by one of Mozilla’s employee, got the sponsorship from the company and had its first public release in 2012.75 Internally Rust code is translated into LLVM Intermediary Representation (IR)76, so any upgrades to performance there directly affect Rust performance. The language employs functional programming concepts like using functions as values, accepting and returning functions from other functions; but also has features of OOP, such as objects and encapsulation, although no inheritance.77 In this section we demonstrate that what makes a language suitable for developing high-performance applications does not automatically make it suitable for game development.
Undeniably the major strength of Rust, is how blazingly fast it is (phrase commonly used in Rust community). It consistently sits at the top 5 in most of the benchmarks.70 Ownership model guarantees memory and thread-safety, although this is a double-edged sword when it comes to game development. Tooling is top-notch and eliminates all the shortcomings that C and C++ struggle with. A compiler provides helpful messages and if a program successfully compiles it will just work.78 Enums and pattern matching is extremely powerful, flexible and intuitive. Being a system programming language, obviously there is a C ABI that allows to include C libraries in Rust code, and export Rust code to be used in C project. Lastly, Rust Traits provide a robust way to enable polymorphism and promote code reuse, which in my experience was much cleaner than mechanisms from other languages. This list can be further extended and elaborated upon by countless articles found on the web, but now it is a turn to evaluate its weaknesses.
The first and immediate issue is slow compilation times, which are largely due to extensive LLVM optimizations. This is exacerbated by the fact that procedural macros (more on this later) do not support incremental compilation and get rerun on each compiler invocation. Although for large non-game companies with virtually infinite computing power this issue can be ignored, game developers, especially indie, do not possess such capabilities and cannot afford such time investment.18
The major obstacle preventing Rust from being the language of choice for game development is how strict are the safety requirements imposed by borrow checker, enforcing programmers to write the “correct” and robust code from the very beginning. Rust’s philosophy frowns upon global mutable state, but games are a collection of a global mutable state.54 Rust will force frequent code refactoring compared to other languages, but considering that game requirements change all the time and new features need to be implemented and tested quickly, this is a fundamental issue. A new type of upgrade can lead to refactoring all the adjusting systems, which might be thrown away after two weeks. What would fit into 5 lines of “hacky” C# script and allow a developer to immediately test a feature in the game and see whether it is even fun and meaningful, in Rust becomes 30 lines of code split into two places. “Working with Unity, most of the work on games ends up being the game, with enough mental energy left to solve interesting problems. While in almost every Rust project I feel most of my mental energy is spent fighting the language, or designing things around the language”.54 Rust will not allow writing ad hoc code and move on to focus on other problem, fixing it later. But game development is not server development, and code will not be always properly organized. Rust’s philosophy emphasizes writing a good code rather than writing a good game.
As the result, ECS model became dominant in Rust game development scene as it provides a straightforward solution to borrow checker. In ECS, object lifetimes are largely ignored, because objects exist as small struct Entity(u32, u32) and do not deal with references. This world model is not used for the performance, or for flat object composition, but rather to solve the problem of “where do I put my objects”. Such widespread presence has turned it from a tool to almost a religious belief.54
Third issue is that like in C++ there is no standard way of getting compile time reflection. The workaround is to use procedural macros, which is a mechanism for running code at compile time, but despite being a powerful tool, they have their own drawbacks. As mentioned earlier, they aren’t cached and get re-run on every compilation. They need to be defined in another crate (package), which forces a project to be split into multiple crates. The learning curve for learning them is incredibly steep, so many projects resolve to use helper crates that take up significant amount of computation. Compare this to how trivial it is to use reflection in C#, it becomes obvious that their usefulness for indie game development is low, as the complexity to use them overweight the advantages of solving minor problems.54
Fourth problem concerns artistic side of game development which is mediocre GUI toolkits. Not UI for an engine, but UI for the actual game that demands high grade of customizability and styling. If you decide to write your own toolkit, you will realize that the borrow checker is nothing more but a hindrance.78 Existing UI libraries have a primary goal of updating data the fastest, rather than being good at making game GUIs.54 There are a lot of game frameworks in Rust, so GUI libraries try to be engine-agnostic, which means that users are left to reinvent the wheel in their own engine of choice if they want something like custom shader effects, particles or animations. This problem can be partly solved with the game engine protocol (see section 2.2.8), but it will not make borrow checker disappear.
Finally, there is a fundamental problem with the community who is so focused on the tech part of development and writing code “the correct way”, that actual game requirements are often overlooked.54 Many projects live on hype and will rise in popularity not based on usability and the amount of shipped projects, but based on how polished is the website or README, flashy GIFs, the loudest promises and the alignment with Rust community values. There is a prevalent property in Rust ecosystem to make users doubt the structure of their code and convince that the project they want to build is not something “you’re supposed to want”. Such obsession with perfectionism impedes game design creativity and turns a video game into a demonstration of software capabilities. But gamers are indifferent about the underlying technologies of a game, they care whether a game is fun and worth their time.
This section might look biased because most of the disadvantages are taken from a single article where author was creating an entirety of the game with Rust. We got a thorough understanding that Rust is performant and safe, but this safety comes at the cost of slow development cycle. One thing an author omitted is that aforementioned safety guarantees are an impedance for a gameplay code rather than an engine code. In Section 2.3.1.3 we wrote about 3 types of speed so let us evaluate Rust based on them. Execution speed is excellent, rivaling C++, just as long-term development speed which is achieved by strict compiler rules. Yet short-term development speed is arguably more crucial in game development which Rust sacrifices for former. Game programmers want to work on their game, not to have fun with type system and figuring out how to best organize their code, and gameplay development is all about squashing different systems together and making it one cohesive whole.
The bottom line is that Rust is a good language choice for writing a game engine, but suboptimal for having the whole game being written in. An obvious solution is to approach this problem similarly to big engines like Godot, Unreal and Unity - write an engine in one language and use a scripting language for gameplay. This approach has proved to work, but as Bevy’s author already stated, it only introduces “runtime overhead, cognitive load and a barrier between me and the engine”. Consequently, this language merely trades a subset of the problems present in C++ for fresh blazingly fast problems in Rust.
2.3.4. Zig
A good middle point between C++ with freedom but no safety guarantees and restrictive Rust with safety guarantees is Zig. It is a new language that first appeared in 2016 and was made to be as performant and low-level as C while fixing many of its problems. It strives to be simple, allowing developers to focus on “debugging their application instead of debugging their programming language knowledge”.79 Before we dive further, it is important to establish that Zig is actually three things in one: 1) a programming language; 2) a build system e.g. cmake; and 3) a C/C++ compiler emphasizing cross-compilation. This means that a build.zig file can describe how to build and link C/C++ projects without having any Zig code in them. Furthermore, because Zig is rather young and haven’t reached its version 1.0, there’s not enough material about how it’s used in production, so similarly to Rust, most of the critique is taken from articles and blog posts of hobbyists and startups, as well as my personal experience.
First, let us discuss the advantages of the language, starting with the speed. As we have seen in Section 2.3.1.3, benchmarks for Zig consistently appear at the top, rivaling C, C++ and Rust. TigerBeetle has benchmarked the throughoutput and latency of their client application in different languages and Zig was also the top performer (1,563,167 transfers per second), prevailing over Go (1,471,084 transfer / s).80 Although internally Zig uses LLVM, which hinders fast compilation speeds, there is an experimental x86 backend that already passes 1884/1923 (98%) tests and dramatically boosts compilation speed. This, combined with (also experimental) incremental compilation, allows compiling half a million line codebase in 14 seconds, while subsequent compilations only take 63 milliseconds.81 Although other languages like Go boast faster compilation times, they have their own drawbacks like absence of metaprogramming tools or fewer optimizations which cause slower executable speeds. This is the dilemma of having either slow programmers, slow compilers or slow execution times82, and Zig prioritizes later two foremost.
Although simplicity does not automatically make software reliant83 and can be viewed as a double-edged sword, I do believe that it makes up for a pleasant development experience, which is important in any kind of development. One of the major design goals of Bevy engine is to be simple - “being easy to use for common tasks without hiding a lot of lower-level details”.47 For this case Zig is a perfect fit, as its syntax is very easy to grasp for anyone familiar with C family of languages (see snippet bellow), and the source code of the entire standard library is accessible for inspection. With the help of LSP (Language Server Protocol) a programmer can jump directly to the implementation of any function or struct, be it IO, math, OS, networking, etc. It hides no under-the-hood details and allows writing applications from the very ground up piece by piece, while keeping it digestible without cryptic syntax. For instance, to concatenate strings one has to do everything manually - allocate the buffer, put strings in there and interpret the content as a string.84
const std = @import("std");
pub fn main() void {
const x = 1234;
var y: i32 = 5678;
y += 1;
std.debug.print("x = {d}; y = {d}", .{x, y});
}
Another more practical feature, directly benefitting game development, is interoperability with C and C ABI (Application Binary Interface). “Although Zig is independent of C, and, unlike most other languages, does not depend on libc, it acknowledges the importance of interacting with existing C code”.79 It is possible to directly import C headers with @cImport and @cInclude, parse them at compile-time, and expose their content as Zig symbols, without any wrappers.83 Even autocompletion will work with C libraries. Moreover, not only is it possible to use C code in Zig, we can also export Zig code into a static or dynamic library to be used inside C/C++ code. This tight integration is crucial for using legacy C/C++ codebases while adopting a new language with a smoother development workflow, saving the budget from having to rewrite everything from scratch.
The build system is written in the same language and is extremely flexible for configuring multiple targets, optimizations, CPU architectures, CLI options and so on. Cross-compiling a project to a different OS, is as easy as adding if (targer.result.os.tag == .windows) {...} to the build.zig file and passing -Dtarget=x86_64-windows flag to a compiler. There is no need to require any specific system dependencies, as Zig is bundled with multiple libc’s: darwin, mingw, musl, glibc and wasi. This also means that there is no need to use containerization software to reproduce the development environment and build for a specific OS.85 The ability to compile a project for any system from any system is a great solution for a porting problem that was mentioned in 8.
No memory management is performed on behalf of the programmer and there is no default allocator e.g. malloc, realloc, free. Any function in standard library that needs to allocate memory accepts an allocator as a parameter. Standard library is designed to be static allocation friendly, for cases when memory upper bound is known in advance. Static allocation helps to reduce the amount of memory used, which means “fewer cache lines fetched from main memory in general, reducing thrashing of the CPU’s cache hierarchy and improving cache hits for optimal performance”.86 Because games are mindful of bounding memory for various tasks, slab and arena allocators are very common, both of which are native allocators in Zig.
Allocation is potentially one of the most expensive things that can happen, and I don’t want to drop a frame because it happened when I wasn’t expecting it. As a game dev, I need to manage my memory requirements up front.18
Such flexibility towards custom allocators can no doubt solve the issues that EASTL tried to fix by rewriting the entire C++ STL.17 However, building a system that allocates memory once at the startup demands careful planning, which is detrimental for short-term development speed. Fortunately, the presence of GeneralPurposeAllocator relieves developers from the burden of having to think about the most appropriate allocator.
Perhaps the most talked about feature among newcomers is comptime - calculating something at compile time rather than doing it at the runtime. It also allows creating new types (generics) at compile time by accepting a type as a function parameter, which is similar to templates in C++, but simpler and more integrated into language type system.83 comptime can also be applied to expressions to determine a value of a constant, for example assigning to it n-th Fibonacci number. Although this feature sure is helpful at certain times and worth pointing out, in my experience it was not as useful for game development as it might appear.
What was incredibly useful, however, is arbitrary-sized integers and packed structs, in particular when interacting with OpenGL or some C library. As an example, consider we need to store the state of our game character. In C++ it would look something like this:
;
struct CharacterState character_state = ;
if
This would be rather wasteful because size of bool is 1 byte, and the total size would be 5 bytes. Usual approach is to store this information as a bitfield inside an integer and perform bitwise operations on it:
// ...
unsigned char character_state = FLAG_IS_ALIVE | FLAG_IS_FULL_HP; // 1 byte
character_state |= FLAG_CAN_ATTACK; // Add CAN_ATTACK flag
character_state &= ~FLAG_IS_FULL_HP; // Was damaged, remove FULL_HP flag
Zig, on the other side, gives us the ability to do the same thing in a more clear way:
const CharacterState = packed struct {
is_alive: bool, // 1 bit
is_full_hp: bool,
can_run: bool,
can_jump: bool,
can_attack: bool,
padding: u3 = 0, // make it 1 byte total
};
var character_state = CharacterState{ .is_alive = true, .is_full_hp = true, .can_run = false, .can_jump = false, .can_attack = false };
if (character_state.is_alive and character_state.is_full_hp) {
// ...
}
character_state.can_attack = true;
Moreover, we can then cast character_state into a c_char and pass it as a bitmask to an external C library.
Despite all these advantages, no language is perfect and Zig comes with its own set of downsides. At the time of writing this, the latest release is 0.14.0, and the road to version 1.0 is long and hard. Every release is accompanied by a list of breaking changes both in a standard library and a build system. Consequentially, documentation is sparse as there is no point in documenting something that will likely be changed in the next release. The best way to learn how a function works is to read the source code and hope there is a test that shows how to use it. While some projects like Bun and TigerBeetle have decided to bet on Zig, there is no guarantee it will ever reach version 1.0.
One side effect of its immaturity is the absence of a concurrency module, because currently is not the primary focus of a development team. The future of async functions is unclear as LLVM currently does not optimize them and lldb (debugger) does not support debugging them.79 As far as I understand, the only way to write concurrent code is to rely on std.Thread and to make use of OS threads. Needless to say, this is detrimental for the ability to optimize games and is a huge roadblock preventing Zig from becoming an ultimate language for game engines.
Other issues are more subjective and stem from the core principle of the language being simple. For instance there are no Traits, which would help to “communicate intent precisely” - Zig’s zen. std.math is full of fn someMath(x: anytype) @TypeOf(x) {...} where x could be anything, and the only way to know its intent is to either read the implementation or pass a dummy value and use the compiler errors as the documentation.87 Meanwhile, fn someMath<T>(x: T) where T: Add + Mul {...} would convey more useful information to users of API.83 There are no destructors, there are defer and errdefer usage of which is not enforced on users except their own meticulousness, again they must know that a particular function expects resources to be de-allocated later. No variable shadowing can sometimes cause a lot of boilerplate code and repetitive variable names. No closures or anonymous functions. Undefined behavior still exists, although there are more checks and tools to work with it than in C. Some compiler errors, like unused arguments, should be warnings instead of errors, as it greatly slows down the prototyping process. Lastly, type errors cannot carry value, like a string describing what went wrong or an integer with an error code.
Finally, certain aspects are harder to categorize into a pro or a con as they are more neutral and are not unique to Zig, but rather to most modern languages, so they are listed here in a matter-of-fact’y fashion. It is important for a compiler to know whether a variable can be mutated (read-write) or not (read-only) to better optimize the code. This is why in Zig variables are prefixed with var or const. Sometimes a variable needs to be declared first then initialized somewhere else, this is why instead of just int x we write var x: i32 = undefined To avoid dereferencing an invalid pointer or having an optional parameter in a function Zig offers an optional ? type var ptr: ?*i32 = null, which will be the same size as a regular pointer var ptr: *i32 = null. There are compiler built-ins, which are the functions sent directly to the compiler and are prefixed with @: @typeInfo(), @TypeOf(), @hasField() and @hasDecl() provide type reflections that C++ lacks, @Vector() performs SIMD (Single Instruction Multiple Data) instructions on a group of the same type variables, @branchHint() allows the optimizer to build the right assembly for cases that you know are more likely to happen than the other, and there are a lot more of them built-ins to your heart’s desire. All files are implicit structs, meaning that big objects can be turned into separate files and @import("file.zig") will treat them as structs. Apart from regular additions and subtractions there are wrapping (@as(u8, 255) +% 1 == 0) and saturating (@as(u8, 255) +| 1 == 255) ones. Destructuring assignment allows unpacking an array or a tuple into multiple variables:
var x: u32 = undefined;
var y: u32 = undefined;
var z: u32 = undefined;
const tuple = .{ 1, 2, 3 };
x, y, z = tuple;
const array = [_]u32{ 4, 5, 6 };
// You can use _ to throw away unwanted values.
_, x, _ = array;
Each function name needs to be unique and functions cannot be overridden because Zig does not allow name mangling. With lazy code evaluation and lazy dependency fetching, you only pay for the parts you use. Lastly, test blocks allow writing unit tests in the same file which are then run with zig test command.
To conclude, Zig enhances C and C++ by bringing modern concepts that are commonplace in contemporary programming languages without sacrificing the executable speed. It is simple, but as in “minimal/not convoluted” rather than “easy to use because it does everything for you”. Its goal is to give developers the ability to build software from bottom up for any platform from any platform. Instead of providing a sugared oversimplified interface, it shows precisely what is what. Unlike other languages that strive to be “C++ killers”, Zig accepts and embraces the importance of C and C++ and chooses to be an autonomous supplement to them. Certain language constructs solve game development needs incredibly well, making it overall a sharp and pleasant tool to use. However, it is still juvenile and is subject to change, which is the opposite of the word “reliable”. Discussion on whether the reliability in relatively short lifespan games is equally important as in critical software is outside the scope of this paper, but in my opinion this tradeoff is worth it, which is why we bother discussing the language in the first place.
2.3.5. C++ vs Rust vs Zig
Now it is time to compare three languages in different contexts so that we can understand the tradeoffs of picking one over the other.
2.3.5.1. Speed
Although rough glance at the benchmarks provided by 70 have shown that all three languages are comparable in performance, let us take a deeper look at them, because in some tests one language can be “substantially faster”88 than another. When comparing C++ with Zig, perhaps the biggest disparity is spotted in a “spectral norm” benchmark that tests mathematic operations on matrices. Typically, those operations in real games will be offloaded to GPU to calculate them in bulk using SIMD, but for these benchmarks everything runs on CPU. C++ code using multi-threading and intrinsic calls (calls directly to a compiler) runs on average ~6 times faster (C++: 39ms vs Zig: 239ms) than single-threaded no built-ins Zig code. N-body test is also skewed because C++ again calls intrinsics and Zig doesn’t, resulting in C++ code to run about 15% faster (C++: 167ms vs Zig: 199ms). For tests on equal footing, like “n sieve” where neither code uses multi-threading nor intrinsics, Zig finally overtakes C++ by 48% (Zig: 287ms vs C++: 489ms), although with high result deviation (+- 11ms). Another factor to consider is peak memory usage - Zig programs tend to be less resource hungry, which is likely the reason of not having a default allocator and having users manage heap memory manually.
Rust benchmarks, on the other hand are not handicapped by multithreading and intrinsic usage, which makes matching it with C++ more fair. “Spectral norm” test shows better results for Rust with a lower input value (Rust: 36ms vs C++: 39ms) but regress with a high value (Rust: 498ms vs C++: 476ms). N-body results are better for Rust, but difference is negligent (Rust: 164ms vs C++: 167ms). “Sieve” test again makes C++ lose with a surprisingly big margin (Rust: 311ms vs C++: 489ms). Peak memory usage appears to be the same for both languages, and is mainly determined by the flags passed to the compiler.
Other aspect of the speed was already hinted when introducing Zig, it is the tradeoffs between slow programmers, compilers and execution times.82 C does not have sophisticated data structures in its standard library and leaves programmers to implement them on their own. This approach makes the language simple to understand and fast to run, but it slows down programmers as they need to implement a lot of functionality from scratch. C++ with templates and macro expansions generates code bloat, and despite runtime speed being comparable to C, takes a lot of time to compile. Lastly, Java code is simple and fast to write as well as to compile, but generated code is less inefficient because most of the data types have to be converted into their corresponding wrapper objects, which creates unnecessary overhead. Rust is similar to C++ in this regard, while Zig leans more towards C approach. This categorization is not as clear as we made it appear, but it is something that can be concluded after using both of them for a while.
2.3.5.2. Object-Orientaion
Next category to compare is instruments to write object-oriented code. Godot has shown that Object-Component world model is important for short-term development speed, mainly because it allows game designers to clearly see which components make up a certain object and understand which component provides the behavior for that object, but also because it promotes code reuse. We can get C++ out of the way because it was designed specifically for OOP, and is a reason why many game developers chose it over C. In Section 2.3.1.2 we learned that an object is a collection of operations on a state. The simplest example is a Transform object: its state is 3 Vector3 values (position, rotation, scale), and its operations might be reset(), move(...), rotate(...), etc. If a language provides encapsulation, it means that we cannot access position directly unless we make it explicitly public or provide a getter method. C does not provide encapsulation, so it is common to access position directly and perform some operations on it. Prototypes, inheritance and polymorphism go hand in hand and imply that a child object can inherit the state and operations from a parent object. A prototype can be:
which can then be inherited by an EnemyDog object:
An EnemyDog will have name, health and transform just as BaseActor does but with different values. This way we can be sure that a method die() can be called on every object in the scene that has inherited BaseActor. This is useful because when a scene grows bigger and more complex, we can be sure that when a player has shot a fourth dog (how cruel), we will call dog4.die() and the engine will handle the dirty work automatically. Polymorphism allows us to treat EnemyDog and other objects inherited from BaseActor as if they were the same thing. For example in order for a player to shoot at something he might have a following function:
And then a script for the actual shooting will be something like this main_player.shoot(&dog4);
Rust has encapsulation - fields in a struct are private by default but can be made public with pub prefix, which is akin to classes in C++. Rust also allows defining operations associated with struct using impl keyword. However, there is no inheritance, nor polymorphism, but this behavior is achieved with a concept of Traits, which are similar to generics in other languages. Implementing a Trait guarantees that an object will have operations defined by that Trait. Continuing with a dog example:
We can be sure that an enemy dog can be shot because it implements a trait Killable. Player struct will have a method called shoot that will accept any object that implements Killable trait:
A script for shooting a dog number 3 will look something like this: main_player.shoot(&dog3); Although this differs from classical definition of polymorphism, this is a powerful feature that in practice is even more convenient because it clearly defines what an object needs to have instead of just vaguely hinting, like a teenage girl, what an object should look like. As for the inheritance, objects cannot inherit each other in Rust.
Zig, being similar to C rather than C++, provides only bare-bones OOP paradigms - a collection of operations on a state, and that is it. Encapsulation exists only at the file level - struct’s private fields can be accessed everywhere throughout the file where this struct was declared, but accessing struct’s members outside that file requires adding pub keyword for member variables or methods. There is no inheritance nor polymorphism, yet there are workarounds to achieve the latter using anytype and @hasDecl() built-in:
const Player = struct {
name: []u8,
health: u32,
transform: Transform,
pub fn shoot(target: anytype) !void {
if (@hasDecl(@TypeOf(target), "die")) {
target.die();
} else {
return error.InvalidTarget;
}
}
}
anytype also solves the problem of lacking function overloading present in C++:
In Zig a similar result can be achieved like this (note that we pass an allocator because the length of a string is unknown, so it will live on the heap):
const GameObject = struct {
pub fn GetType(allocator: std.mem.Allocator, arg: anytype) ![]u8 { // returns an error or a string slice
const T = @TypeOf(arg);
return switch (T) {
u32 => try std.fmt.allocPrint(allocator, "Object ID # {d}", .{arg}),
[]u8 => try std.fmt.allocPrint(allocator, "Object Name {s}", .{arg}),
else => try std.fmt.allocPrint(allocator, "Default Object", .{}),
};
}
}
To some it could be viewed as a workaround rather than a solid solution, only reinforcing the argument that Zig does not provide necessary means to “communicate intent precisely”. On the other hand, perhaps certain established OOP paradigms are redundant altogether if a programmer has access to type reflection. Only time will show. It might be possible that all a game engine needs from OOP is a “collections of operations that share a state” absent in C. Nonetheless, many workflows rely on inheritance and polymorphism extensively, meaning that, objectively speaking, Zig does not provide adequate tools to implement Object-Component world model.
2.3.5.3. Memory safety
Next subject to discuss is memory safety and what strategies these languages employ to prevent programmers from accessing objects that are no longer valid. C being the oldest and simplest does not offer anything valuable and forces programmers to practice utmost care when allocating objects on the heap. Rust has the most amount of tools to avoid causing undefined behavior. Firstly there is a concept of ownership that dictates following rules: 1) each value has an owner; 2) there can only be one owner at a time; 3) when owner goes out of scope - value is de-allocated.77 Another important concept is a borrow checker - you can borrow a value from its owner without taking ownership of it. It is similar to pointers in C, but with an important distinction that there can only be either one mutable reference or many immutable references. Here is an example:
Borrow checker makes sure that there will never be an invalid pointer, because if the value has been destroyed, so had the reference to it. Apart from raw pointers and references observed in C, Rust offers “smart pointers” which are pointers with helpful information attached to them, which usually take the ownership of the data they point to. Most common are Box<T> which is the simplest one and similar in functionality to regular pointers, Rc<T> (reference count) allows having multiple owners that point to the same data, and different flavors of cells Cell<T>, RefCell<T>, OnceCell<T>, LazyCell<T> exist to bypass the rule of having only a single mutable reference.89
C++ possesses multiple types of smart pointers: unique_ptr guarantees that there is only one reference to the object, shared_ptr is similar to Rc<T> in which it allows to have multiple owners of the object, and its sibling weak_ptr allows having multiple references that do not own the object. The ownership of the data is not explicitly enforced as in Rust, however, there are mechanisms that help with managing the life-cycle of objects. One of them is RAII (Resource Acquisition Is Initialization) which we will cover shortly, and move constructor (also referred as “move semantics”) provides the same behavior as ownership in Rust, although being more syntactically verbose.90
As for Zig, there are no smart pointers on language level, but they can be implemented manually since they are just an advanced struct. However, unlike pointers in C and C++ that simply store a location in memory, in Zig there is a slice which is a pointer and its length, a C-like pointer to one item, a pointer to unknown number of elements, a pointer to unknown number of elements that are null-terminated and optional pointers that can have either a valid value or null.91 These instruments do not make Zig a memory safe language, nor do they make it stringent, they merely provide handy tools for developers to write memory safe code. “It is the Zig programmer’s responsibility to ensure that a pointer is not accessed when the memory pointed to is no longer available”.79
As we have discussed already, one of the problems of C and C++ is undefined behavior, which is still present in both languages. Arguably Rust provides a lot of safeguards helping to eliminate it, but developers can still cause it when writing unsafe code, that is a code block on which borrow checker does not enforce its rules. While in Zig it is called illegal behavior and there are more tools to detect it both at compile- and runtime. Rust makes it very hard to leak memory while Zig threads the path in between C++ and Rust, trying to provide meaningful instruments while not being overly pedantic. It also helps that when a global allocator fails, Rust program will panic and crash, while in Zig it will return an error which can be recovered from.92
2.3.5.4. Lifetime management
In C++ RAII helps to deal with the resource ownership and lifetime of an object aka how long it should be valid. When an object is first created, the constructor will try to acquire the resources it needs, and similarly when this object goes out of scope the destructor will clean those resources up.
RAII is a good strategy, because its usage is not enforced onto programmers but exists rather as a choice not impeding the workflow.
In Rust, lifetimes for references must be annotated explicitly:
Such approach is great to ensure that a reference to an object cannot outlive the actual object. It is also explicit and clearly shows the intention of the code, helping developers that work on different code parts understand the connection between objects. On the flip side, it also means that programmers have to think in advance about such an irrelevant thing as the lifetime of one reference in relation to another.
In Zig lifetimes of objects are managed more generally with allocators. It is both more simple and flexible compared to Rust because instead of manually specifying a lifetime for every dynamic object, a programmer can manage them via an appropriate allocator, such as resting an arena allocator clearing everything there all at once when a level is finished, or de-allocating a specific object from a general purpose allocator, such as current details about the level.
2.3.5.5. Error handling
C++ exceptions are allocated in dynamic memory and thus a compiler cannot properly apply optimizations on them. But the bigger problem with them is how unpredictable the overhead is when the program is run on a multicore system - just at 1% failure rate the execution time spikes by 10%, while at 10% on a 12-core machine the overhead reaches staggering 1300%.93
Rust approaches errors from a different angle - they can either be recovered from thus not affecting the program’s execution flow, or they cannot be recovered from thus aborting the program.77 Recoverable errors are wrapped in a Result<T, E> enum type, where T is the value returned when the operation succeeds and E is the type of the error. For example, when a game wants to open a file that represents a saved game state, it can fail because there is no such file. In this case a function that opens a file will return Err(E) which can then be handled by creating a new blank game state, or just ignoring the error completely and starting a new game. Whilst if a function returns Ok(T) it means that a file has been opened, and we can initialize game state to the data from that file. This approach is both performance-efficient and simple to use, since recovering from errors does not cause any more performance penalties than an if-statement.
Zig approaches error handling similar to Rust by allowing to recover from errors. Instead of wrapping them in Ok(T) or Err(E), a normal type can be combined with an error type into an error union type using ! operator. A valid value can be const x: anyerror!i32 = 1234; while an error const y: anyerror!i32 = error.Failure; Apart from this distinction, Zig errors behave the same as in Rust and a very pleasant to work with.83 This strategy allows a compiler to optimize the erroneous code because it knows precisely what kind of errors can be returned by each function.
2.3.5.6. Tooling
This is perhaps the most contradicting section in this chapter because it is not always clear how much variety is optimal until it becomes harmful. We have already mentioned in section 2.3.2 that C and C++ have poor tooling, but perhaps the right word is “convoluted” tooling. There are many different compilers because there are different schools of thought. Correspondingly, there are a lot of standard libraries, package managers, build systems, debuggers, you name it, all of which are trying to fix issues present in their peers. It is also a sign of a mature and widely adopted product. Variety in Rust is nowhere near close - there is gccrs project which aims to replace the default LLVM backend with GCC to capture a broader platform support, and Cranelift which generates its Intermediary Representation (IR) and then compiles it into machine code, bypassing the need for LLVM completely. While in Zig there is only LLVM and its own backend for x86. Here we compare tooling in regard to just a single aspect of software development - code reuse.
In Section 2.3.1.1 we have discussed the conceptual size of software building blocks and how the abstraction piles up until those building blocks become indiscernible. This is the job of a package manager - to specify how to assemble those building blocks into a usable software “construction site”. Rust’s Cargo wins the fight of user experience hands down. It is unbelievable how easy it is to pull in external library (a crate) into a project for a low-level, systems programming language. The experience is very similar to JavaScript’s npm, but I cannot comment on it in detail because I am not a web developer. Crates.io - a registry website that hosts Rust crates currently has over 178_000 crates, which might not be as much as npm or even existing C libraries out there, but considering how accessible they are, a programmer can be certain that he won’t need to rewrite already mentioned building blocks from scratch and instead can focus on implementing the higher level logic of a program.
In contrast, typical setup for C/C++ project involves building necessary libraries by following authors’ instructions or requiring them from the operating system, validating that they are correct, linking them to the project, and then repeating the processes for every target platform. If a library provides only a single build system file which your project doesn’t use, then the process is even more delightful. zig.build provides a modern solution to this by simplifying the step of porting a library into another platform, but on the flip side it introduces yet another standard.
As of now there is no central registry to host Zig packages, but there are community projects that scrape repositories like GitHub and search for projects with specific topic like “zig-package”. On the bright side, any C and C++ library can become a Zig package as long as someone is eager enough, however, considering that Zig is still evolving, it is very likely that on next major release this package will fail to build. Additionally, every build.zig.zon file that describes a project’s structure and external dependencies requires knowing a hash of an archived source code, for which there is still no one-step-solution to get it. Overall, Rust ecosystem currently offers much smoother experience than Zig, yet both of them are more convenient and straight forward than that of C and C++.
2.3.5.7. Miscellaneous
Some lesser aspects would not justify a separate section for each, so they are gathered here. Documentation in Rust is taken with utmost care, which can be seen browsing both standard library or any of “books” that explain different parts of the ecosystem from the language introduction to the internals of a rustc compiler in comprehensive details. Package authors do not need to include any external utilities to build the docs as it is included in rustup toolchain, and their libraries will have the same treatment as the standard one.
Zig’s approach is similar in being accessible offline and in being built into the toolchain, but arguably less polished. Language reference is very well written, explains everything a programmer would need to know and is stored as a single webpage, making it convenient to search for specific keywords. What lacks, however, is standard library documentation. Constrained by the fact that the language is young and changes frequently, it is to be expected, but it doesn’t mean this fact can be overlooked. Entry barrier can sometimes be unexpectedly high, requiring a long read-through of the standard library module to grasp the idea how a certain feature works.
C and C++ do not supply default documentation generation tools, but there are a variety of doc generators like Sphinx, Doxygen or hdoc. Each of them require specific syntax, so using one implies learning how to set it up and sticking to it. It is not rare for a project to be documented in either headers or Markdown files living in a /doc folder.
Another lacking feature of C++ is a test runner. Both Rust and Zig offer built-in testing framework that is trivial to use and integrate into CI/CD, whilst C++ relies on third-party libraries for testing, and we have already discussed how enjoyable the process of importing libraries is. On the bright side, there are variety of them, to the surprise of absolutely no one, all of which offer unique workflows and a list of pros and cons.
2.3.6. Takeaways
C and C++ are well established languages in the game development world. They run fast, their compilers support a wide range of target platforms, and they do not make any assumptions about the program, letting developers be responsible for writing high performance code. However, they carry the legacy of the ancient design choices which in the modern world are often redundant and even harmful. The differences in game development and regular software development often cause programmers to either completely ignore certain language constructs, or reimplement them from scratch to better accommodate the nature of the game. Moreover, their ecosystem is so disjointed that the development environment for any big project is inevitably biased and limited to a specific operating system and toolchain. This bias increases the friction between developers and a product, since joining a new team will often require accommodating to a new tooling before one can make any progress.
Rust tries to fix many existing problems of C++ from deep down, and is very successful at it. A side effect of this approach is a relatively steep learning curve, as many concepts it introduces will be novel to most programmers. However, once this barrier is overcome, this language and tooling will feel very natural and enjoyable to use. Runtime speed of Rust applications competes with ones written in C++, all the while ensuring that there are no weak spots that could crash the program. The major roadblock preventing it from becoming the perfect language for game development is strict and rigid rules enforced by a compiler. Unlike operating systems or other security vulnerable programs, the nature of games requires writing imperfect, ad hoc code that might be thrown away later, which Rust heavily discourages. Games do not simulate the reality, they imitate it, which means cutting corners and preferring speed and performance to correctness. It is viable for writing an engine that will be used as a game core and providing a simple scripting language to create gameplay code, but this approach only introduces a barrier between a programmer and the engine and causes redundant complexity.
Zig likewise aims at solving problems present in C++ albeit differently. Apart from introducing modern concepts that fit game development needs and ease the production workflow, it has embraced the ubiquity of C and C++ and tries to the supplement to them instead of complete replacement. Zig can compile C and C++ code and describe how to build it, replacing both a compiler and a build system. Thus, instead of rewriting the hole project from scratch, one can simply rewrite parts that need it, incorporating modern instruments into a legacy project. Combined with how minimal and intuitive this language is, it has the potential to provide the most optimal way to expose the continuous chain from the engine’s core systems to gameplay code, solving the problem of ever-growing abstraction and complexity. In fact, some of the best practices of how to write game libraries 94 reside in Zig natively on a language level. The most noticeable one is no memory allocation for the user and explicitness of const and var values. It does not rely on OS dependent parts of libc because Zig already ships different versions of libc’s. “C is the lingua franca of programming. There are many advantages to writing your library in C…”, and Zig provides excellent interoperability with C.
Writing Zig code sometimes can be more verbose than C++, but this is for the sake of being predictable and easy to understand, which cannot be said about C++, especially when reading metaprogramming code. Nonetheless, Zig allows cutting corners unlike Rust, where writing code can feel like puzzle solving.84 On the other hand, working inside strict rules can sometimes make coding easier because there is a clear “correct” way how to implement specific functionality.
The biggest threat comes from the fact that this language is still in early development and changes frequently and drastically. This might not matter much for smaller indie companies, but big organizations should probably stay away from it for now. Despite that, some companies have already invested in Zig (TigerBeetle, Bun) and a company the name of which is undisclosed has chosen it over Rust for how simple it is to port software to different platforms, reuse existing C libraries, and easy to learn.88 Those advantages overtook Rust’s major strengths - memory safety, active community and rich ecosystem.
With all that said, however, it is impossible to establish which language is objectively better for game development, let alone perfect. Here is an argument for preferring Rust over Zig:
…while Rust “is not for lone genius hackers”, Zig… kinda is. On more peaceable terms, while Rust is a language for building modular software, Zig is in some sense anti-modular.95
Author then states that writing memory safe code is not the problem, the problem is establishing the boundaries and contracts between components which are enforced by a machine. This is what Rust does, and as such Rust projects scale better, making it a splendid choice for using in big corporations. On the other hand, Zig
is aimed at producing just the right assembly, not allowing maximally concise and abstract source code …Zig is about perfection. It is a very sharp, dangerous, but, ultimately, more flexible tool.95
This perfection and “producing the right assembly” fits a bit too well for the engine of the future described by Pesce:
The state of the art lies in touching as little memory as possible to initiate work …the art of a contemporary real-time engine is in how to thin down the inevitable communication from the CPU (typically, game logic, scene updates) to the command buffer generation.96
In other words to generate a command buffer in as few clock cycles as possible and by referencing as little memory as possible. He then elaborates further by stressing the importance of effective memory management:
If we were to write an engine today, its role would be entirely around resource management, nothing else, on the CPU. Manage memory pools, swapping (streaming) resources in and out - effectively, the CPU knows about the world and its dynamics, and it constantly has to figure out what subset to expose to a GPU, in the most efficient way.96
Ultimately, it all comes down to personal preferences to pick a tool that feels comfortable to use, but I hope that a title of this paper will hint which one of them will feel the most comfortable for creating a game engine of the next generation.
3. Results
3.1. Game ↔ Engine
The line between a game and its engine, despite being blurry, can be traced down. It is as easy as differentiating a gameplay script and the engine code. However, in reality what appears to be a “finished” game can still be modded and repurposed into a new product, becoming its very own engine if community is passionate enough. We have seen some examples how a number of companies accommodate the tools to let players create the content for their games, and in fact this trend was already spotted by Gabe Newell back in 2013: “Games are becoming nodes in a linked economy where the majority of digital goods and services are user generated, rather than created by companies”.97 Taking a look back at Section 2.2.6, we found that Godot engine practices “dogfooding” their own tools, which is akin in nature to game modding - building a game content using the exact same toolset that is given to the players. Gregory distinguished this module as Gameplay Foundations (GMP) - the topmost layer of RTEA which links all engine’s functionality together to allow creating Game-Specific Subsystems - a module that lies beyond RTEA as it is what makes up a concrete game.
An engine of the future should be blended with games it creates into a one contiguous stack. Tools of GMP module that game developers use to build the game content are not a government secret, and can be safely shipped with the game to let players build up the game and mold it into what they deem fit. As a developer, you cannot control what content needs to be created, but you can shepherd the community into the right direction by exposing the appropriate tools. The engine that allows controlling the behavior of the game without writing any code is called data-driven engine (chpt 15.3)10. This approach keeps designers close to the game53 and gives them more responsibility over game’s trajectory of development. A recent example of this style in action is Epic’s Unreal Editor for Fortnite, which simplifies visual programming from blueprints in Unreal Engine into a “device programming” workflow, where game logic can be created from within the actual game using visual objects that can be placed inside a game level and tweaked to perform certain logic: triggering an animation sequence on some event, spawning new entities and even controlling settings of the game world.
One of the reasons why Unity remains popular is its rich community, in particular community generated assets, tutorials, tools and active forums. The engine can only become usable when people start creating real games with it, report their experiences and share some content. This cycle allows consequent game developers to re-use some of that content and build games upon it rather than making new ones from scratch. The integral part of the next generation engine is ease of sharing and reusing the content, as even nowadays, game engines are a collection of reusable components.6 “Game forking”, for example, can take inspiration from the software development domain to allow game developers using another existing game as the foundation for their own, massively speeding up the early stages of development. Alternatively, a more traditional approach is to have a marketplace, a database or an indexer where users can share their creations that can be imported into a new project from within an engine.
Nonetheless, such strategy is not without its flaws. A game is a set of rules and constraints imposed on a player. Just like using game cheats can allow players to bypass those constraints and engage with a game in an unintended way, exposing unrestricted modding tools can quickly lead players to boredom because in many cases it is the challenge and odds that make a game worth playing. A great example of this phenomenon is depicted in Twilight Zone episode 28 where a criminal gets the ability to get anything he wishes, making his life an unlosable game. Soon after, he realizes that such power is a curse, not a gift. Similarly, exposing players to GMP module to extend the game bears the danger of giving this kind of power to them. A perfect combination of a game that is its own engine is the one that does not disrupt the flow of the existing game, but allows reusing existing game’s building blocks or extending that game with a new content.
In section 1.3 (Terminology) we gave our own definition of the term “game engine”, but now let’s adjust it to reflect our finding. “Game engine” is an ecosystem around software development, which helps with producing and extending video games in one way or another. The notion of reusing and extending any projects inevitably brings us to the world of open source software and different licenses. Politowski et al. regarding this write following:
Open source is the right path to follow. It democratizes and allow a soft learning curve for beginners. Also, it will allow the creation of more diverse games.3
I firmly agree with them, but have an extra remark: the reality of capitalist economies is that companies want to stay ahead of their competition, which means not sharing more than needed. An engine with a GPL or similar copyleft licenses will never have a chance to succeed. A license should be as permissive as possible to let managers and higher-ups be certain that the product they are working on will belong to them, and they will have exclusive rights to it.
3.2. Pre-production phase
None of the current generation game engines offer any meaningful tools to handle pre-production problems, which form a sizable chunk of all game development problems. An engine must incorporate tools that aim specifically to make a transition from a game idea into a prototype into a working game as smooth and as fast as possible. This includes requirements specifications, standardized Game Design Documentation that can be mapped directly to an engine’s API, and miscellaneous instruments to handle project management, testing, verification, etc. Correct specification of requirements allows working in a custom-tailored engine designed to create a specific kind of game, which limits the flexibility, but boosts developers’ productivity.
Another area for which an engine should take more accountability is Digital Content Creation (DCC) module - 3rd party software. Triple-A game engines employ asset conditioning pipeline to transform game assets from their original format into the one supported by the engine. But the flaw of this system is that it only goes in one direction. An artist creates static content which is imported into the game, receives feedback, modifies it and the cycle repeats. A 3D modeler will be much more productive using his favorite software than any possible simplest engine. Thus, a next generation engine is the one that non-programmers do not need to know anything about, and apart from allowing to import static content also allows exporting game content into DCC, so that artists can work on dynamic contents of the game in their software of choice. In a way, this engine serves as the basis that links different programs together to form a cohesive whole. The demand for unifying different engines was recently introduced by Bethesda’s remake of Elder Scrolls 4:
The original Oblivion is still the heart and soul of the remaster, but we use Unreal Engine 5 to help achieve all our visual goals. We think of Oblivion game engine as the brain, and Unreal 5 as the body.98
Ideally, it is also decoupled from operating system specific dependencies, to give developers the ability to work on the same game project with different development setup:
…Windows was not meant for the type of development necessary for video games. Microsoft Visual Studio was built for Visual Basic and C# mainly, not for C++, but the only viable C++ compiler and environment on Windows remains Visual C++.8
In a case when a team is small, consisting from one to five persons, an alternative approach to reduce pre-production problems is aforementioned “game forking”. Instead of building a game from bottom up, you start from top down. This is suitable for game ideas, the pitch of which is described as “Like game X, but you can do Y”. Additionally, this approach should yield benefits when teaching specific aspects of game development, because firstly, as a member of a team you are more likely to integrate your work into existing project, rather than start from scratch, and secondly, it provides an instant visual feedback that can be observed and impact the rest of the game. For a realistic example of game forking, imagine a third-person survival sandbox game that is born as a copy of another game but with minor changes in level layout, then movement system, modifications to UI and finally addition of brand-new mechanics. Obviously, this is not a friendly approach for money making, but we need to keep in mind that there are people out there who want to create unique games for the sake of self-expression rather than to make living.
3.3. Game engine protocol
Although Gregory has described how an engine architecture can be implemented (RTEA), we observed that on practice some engines follow RTEA to a tee, while others approach the architecture in a completely novel way. Different design philosophies lead to completely different workflows and different ways to organize games’ structure. This diversity makes it difficult to answer ANENLOCO-1 - how to properly define any given engine and each of its components.
The most academically sound approach to such problem is to develop a standardized game engine protocol. This protocol describes all potential components any given game engine can have, and these components’ inputs, outputs, dependencies, etc. Not only that, but it also serves as a logical link between Game Design Document and engine components. Early stages of the draft should primarily focus on the topmost layer of the engine - Gameplay Foundation (GMP) and how it interacts with underlying components. This layer is where a game genre is usually defined, where base building blocks with which a game will be made are formed, and this layer is the least reusable across different games. A protocol that describes how engine components can be assembled together solves flexibility limitations because with a clear scheme potentially any component can be plugged in and out, meaning that an engine can make use of a wider variety of existing libraries, as long as they conform to the protocol.
A protocol also directly solves the concerns of ANENLOCO-4 - how to minimize the impact of the future advancements in computer game technology on the top-level game design. As long as the engine conforms to the protocol, designers can be certain that top-level systems will remain the same and their workflow will not be impacted when new optimizations are being introduced. In fact, the entry barrier for applying deeply specialized knowledge -
…engine code, depth of simulation, and profiling as some of the highly domain-specific requirements that contribute to the difficulty of writing video games …mathematical and algorithmic knowledge and the wisdom to know how the algorithms will interact when coupled together8
should only get lower when a person with such knowledge can clearly see in which ways specific components are linked together.
In practice, this allows developing engine modules in separation and in theory introduce engine distributions, taking inspiration from Linux ecosystem. Instead of a bulky monolithic engine, game developers can choose which modules they would need to make a specific game - assembling a working game engine from smaller pieces, or reusing low-level core systems to avoid unnecessary bloat. This promotes creativity not only of the game design, but also of the software design, which can lead to more diverse and unique games. Such freedom is another aspect of what constitutes a next generation game engine.
However, a safety precaution must be taken when designing such a protocol as to not make it overly restrictive. In particular, to avoid limitations around Game World Models. We have seen that each model offers unique advantages: Procedural model produces smallest executable size; Object Component Model (OCM) is conceptually simple to reason about; and Entity Component System (ECS) is pretty modular and offers great performance for densely populated worlds. Instead of being restricted by a particular model, a next generation game engine should leverage and combine the best of all three models on demand. As an example, an engine for a city building game should incorporate more features from ECS model, while an engine for making small games that will be played on embedded systems should possess more features of the Procedural model.
3.4. Zig
C and C++ are omnipresent in game development, but they also bear old philosophies and constraints that are no longer relevant in modern programming. There is a wide variety of programming languages in the wild, including Rust, design goals of which is to fix issues of C++. Quoting the inventor of C++, “There are only two kinds of languages: the ones people complain about and the ones nobody uses”72 - valiant words that only a winner of survivorship bias has the right to muster. History was full on “C++ killers” who failed to take off and met their demise still in the infancy. The reality is that legacy systems will continue to be the backbone of numerous modern software. While it might be easier to make a game from total scratch in Rust rather than in C++, it is much easier instead to write whatever C++ code on top of a popular and well-maintained library.52 Zig is not the only language out there that seamlessly integrates with C, but it is more than just a language - it is also a build system that allows to seamlessly mix and match C, C++ and Zig code in a single codebase, as well as to create executables for different target platforms, removing the necessity to create and manage virtual environments for each of them. Such mixture of classic and modern is genuinely refreshing to see.
But why is it the foundation, and not just a language or even an ecosystem for a next generation game engine? If we take a look back at RTEA or even Taxonomy of Game Engines15, the lowest component in the hierarchy is called “Core” - useful software utilities. This is the most highly coupled subsystem in the whole engine and other components directly rely on it for their operation.12 According to Linux manual page, “libc” is a library of standard functions.99 Those two concepts are closely intertwined, as both libc and COR module serve the purpose of providing basic software building blocks for higher-level applications. One of the earliest big games that was written in C++ was Doom 3, coincidentally by the very same people who coined the term “game engine” (Section 1.3). It did not use C++ template library, flaws of which we have already seen, however, libc was extensively used.100 Zig ships multiple versions of libc to target different operating systems. Moreover, its standard library has no hidden memory allocations, again solving problems of C and C++ standard libraries. If any function there needs to do some compiler magic, it will use built-ins prefixed with @ sign. This approach makes Zig’s standard library as plain and transparent as possible, not giving it any more privileges than to other user-written libraries, and providing the perfect foundation for writing useful software utilities suitable for game development.
There are three kinds of speed important for game development, and Zig balances them in a manner that is optimal for game software. It’s execution time is very fast, rivaling that of C, C++ and other languages known for their runtime speed. This, however, does not sacrifice short-term development speed, as the type system is not overly strict, and, although being statically typed, oftentimes type declarations can be omitted because they will automatically be inferred from the context. Sure, it is not as malleable as, for example, JavaScript that permits unimaginable spaghettification and even casting unsigned Toyota Yaris 2002 into float, but it is still fine for writing prototype code. Long-term development speed is harder to measure, but minimal syntax makes it easier to digest big chunks of code, and from what can be observed by reading standard library, it is trivial to write a program in a way that new contributors can make a progress quickly, focusing on debugging the game rather than debugging their programming language knowledge.
The biggest roadblock to be aware of, is that it still has not reached version 1.0, which means anything can change. This makes user experience very coarse at times, forcing to choose between either using legacy API or refactoring a build system on every minor release. Because so many pieces are subjects to change, it means that the code is the documentation, and for anything more advanced than reading a file, users have to invest time to read the implementation of standard library to understand how to use it. Integrating Zig into a project’s workflow means taking high risk to reap high rewards. The potential for program optimization is great, as well as to improve developer experience, but until it reaches a first stable release, a big part of biweekly routine will have to be spent on maintaining the ever-changing infrastructure, which requires build engineers, but “employing people in non-game engineering roles is a systemic problem of the games industry”.18
3.5. Discussion
The original aim of this study was to discover different game engine components and evaluate whether Zig ecosystem is suitable and mature enough to implement them. Very quickly it became apparent that this field is still not adequately researched, as even the term “game engine” is dubious and can describe both a core engine to the entire production pipeline.15 In the end, we tried to fill some of the gaps in current state of research, in particular 5 concerns raised by Anders et al. Problems number three and five (ANENLOCO-3, ANENLOCO-5) were not addressed at all, for ANENLOCO-1 and 4 we suggest designing a standardized game engine protocol that describes the relationship between engine components and how they can be assembled to form a base for the Gameplay Foundation (GMP) layer. ANENLOCO-2 question is highly debatable, but here we suggest disregarding the line between a game and its engine because no game is ever in the final form - community can build a new content upon it, turning a game into its own engine. Nonetheless, perhaps we do need to draw the boundaries between them. If so then what for?
We also suggested that the engine should be aware of third-party software used for asset creation. On one end of the spectrum we can have complete decentralization of components where an engine is simply a collection of different programs: 3d editor, audio mixer, graphics engine, world editor, etc., while on the other hand we can have a huge monolith with optional components, where the engine is actually a single self-sufficient program that can create a game of any genre. Again, to have an actual choice, we need to have a universally agreed way of describing how to connect different pieces together. This is not only about the engine protocol, but also about scene description. Formats like gLTF and USD are quite common, but they only describe static content, nothing about gameplay elements. One of the difficulties is that there are different game world models (Section 2.2.2), which force their own rules for scene description. ECS is gaining popularity, but there are no systematic solutions for many use cases and very often it only forces the creation of redundant complexity to solve basic problems.101
Game engines vary in their scope, some offer more functionality while others stay minimal. Yet even giant Unity and Unreal do not address pre-production phase problems. None is offering to integrate early game design documents into the engine to speed up the prototyping stage. Game development management, requirements specifications, project planning, marketing strategy and risk management are integral steps for any successful game project2, yet every solution offloads this responsibility somewhere else. “Game engines are tools that help game developers to build games and, therefore, are not directly concerned with non-functional requirements of games, such as “being fun””.3 But perhaps this is a good thing - separation of concerns prevents an engine from gaining user majority and forming the monopoly on the market.
Lastly, we raised the question of migrating game development into a modern programming language, which can seamlessly integrate with existing C and C++ codebases. Zig was our primary choice, but it is not the only alternative. Moreover, due to the young age, most of the information used here is gray literature taken from technical articles of hobbyists and startups. In fact, the state of the art game engines are behind closed-source and are huge in their scope, meaning that the information we took to analyze open source game engines also comes from gray literature and might not generalize the trends of game engines too well. There are plenty of open-source engines, but not a lot of open-source high-grade games, which makes studying them particularly challenging. Engines by themselves are not of much use, and can only be relevant for research in conjunction with full-scales games made with them.
4. Conclusion
This research is almost done, and the only thing left is to summarize what we have learned before we can finally close this tab and move on with the rest of our daily routine. It started with the analysis of two most popular general purpose game engines, Unity and Unreal. There we found that all their benefits can be broken down into 4 categories: portability, versatility, graphics and community. Respectively, the ability to run games on different platforms, to use a diverse toolset that accommodates different game genres and requirements, to make use of the latest features of graphics cards and pursue different art directions, and to be surrounded by fellow developers who can assist either in a form of tutorials, plugins, answers on forums, code snippets or free assets.
Engine analysis consisted of three parts. First was a breakdown of engine architecture - how different modules are organized and what do they do; and of different game world models - organization of game objects in a scene. We also took a paper by Anderson and colleagues from which we extracted 5 fundamental questions regarding the gaps in the existing state of research on game engines, and slapped an unnecessary abbreviation on them in order to pay the respect to all the authors. Second part was the actual analysis of open-source game engines and how they fare in portability, versatility, graphics, community, architecture and world model. Third part discussed game modding as the form of game development and how it logically fits into Gregory’s Runtime Engine Architecture model. We concluded that a game and its engine is a one continuous whole and there is no actual benefit trying to discern gameplay code from the engine code; one of the drawbacks of open-source engines is their neglect towards pre-production phase problems e.g. no integration of game design document; that engine components and thus architecture and world model can be combined in multiple ways with no right or wrong approaches; and finally the more of the game requirements are known in advance, the more precise and opinionated can engine functionality be, simplifying the developers’ life, but limiting the game’s flexibility.
Programming languages analysis had more technical tidbits because we had to understand the requirements imposed on a language to make it suitable for writing high performance games. There are three kinds of speeds: executable runtime, short-term and long term development. An optimal language must balance all three of them, which is not too simple because of the slow programmer/compiler/executable dilemma. Zig is not a perfect candidate, but it slightly outcompetes his peers C++ and Rust overall. The only thing to be aware of is that it is in early development and changes frequently.
Our most notable result was the introduction of the game engine protocol - a way to describe how different components fit together. It has a few interesting implications that can change the direction of how game engines evolve. Firstly, it can solve the limitation of engine flexibility while not overwhelming designers with the vast toolset. Secondly, it significantly reduces the time to translate a game idea into a playable prototype, as requirements specified in game design document can be clearly mapped to the topmost layer of the engine, listing what functionality is required from it. Thirdly, if we consider that a game is the extension of the engine, it means that an engine can also act as a game distributor, hosting different games in a single game world. Exercising in mental gymnastics even further, we can imagine how an engine can also take care of OS and driver layers and become the only runnable application on a system, taking care of hardware resources and minimizing system requirements. Sky is the limit, as they say, and nobody can predict the future.
Ultimately, this paper tries to be a stepping stone in bringing new advancements in the field of game engine architecture and design. For how big video game industry is, game engines are surprisingly disjointed and not standardized. In culmination of our exploration, it is only fitting to conclude with the words of Unreal’s creator and industry pioneer Tim Sweeney:
So many companies are now crippling their production process by building engines that are perfectly fine with tools that are not fine at all. It’s always the tools that kill people.
…everybody should really make a conscientious decision to either fully invest in producing awesome tools for internal use, or not.
It’s not only for the 3d editor used to build your levels, but it’s your build system, and it’s your programming language, it’s your production pipeline, it’s the DCC tools you use, all of that.
Tools are supposed to have a multiplying impact on productivity, and when you find that they have a dividing impact on productivity, get the hell out.46